Regression to the mean, RTM for short, is a statistical phenomenon which occurs when a variable that is in some sense unreliable or unstable is measured on two different occasions. Another way to put it is that RTM is to be expected whenever there is a less than perfect correlation between two measurements of the same thing. The most conspicuous consequence of RTM is that individuals who are far from the mean value of the distribution on first measurement tend to be noticeably closer to the mean on second measurement. As most variables aren’t perfectly stable over time, RTM is a more or less universal phenomenon.
In this post, I will attempt to explain why regression to the mean happens. I will also try to clarify certain common misconceptions about it, such as why RTM does not make people more average over time. Much of the post is devoted to demonstrating how RTM complicates group comparisons, and what can be done about it. My approach is didactic and I will repeat myself a lot, but I think that’s warranted given how often people are misled by this phenomenon.
[toc]
1. Three types of RTM
As I see it, there are three general reasons why RTM happens: random measurement error, sampling from the tails, and non-transmissibility of otherwise stable influences. I’ll briefly go over what I mean by them first.
1.1. Random measurement error
Any given variable will usually be measured somewhat imprecisely so that the values obtained do not necessarily correspond to the true underlying values. The extent to which a given observed value of the variable differs from the true value because of measurement error can be referred to as an error score. Error scores always “strike” individuals (or other units of analysis, e.g., companies, cities) randomly, and therefore are different from one occasion to another. If you get a large error score on first measurement, you will likely get a small one the next time simply because smaller error scores are more common than large ones. For example, if you take a difficult multiple-choice IQ test and make several correct guesses when you don’t know the answers, leading to you getting a very high test score, your score when retaking the test will likely regress towards the mean as you will probably not be as lucky with your guesses the second time around.
This graph demonstrates how IQ scores, represented by the grey dots, regress towards the mean in a large sample of individuals:
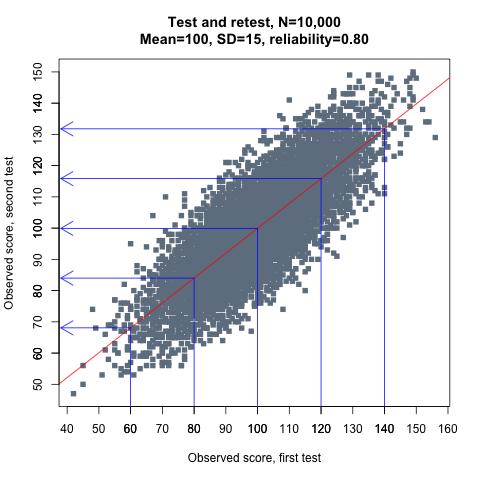
Figure 1.
IQ scores obtained on first testing are on the x-axis, while retest scores are on the y-axis. The test has a mean of 100 and a reliability of 0.80, and the red line is the line that best predicts an individual’s retest score based on his or her score in the first test. The blue lines with arrows highlight the varying magnitude of the regression effect at selected IQ levels. As can be seen, low and high scorers tend to be more average when retested. For example, those scoring 80 in the first test average about 84 in the second test, while the average retest score for those who scored 120 is 116. This (simulated) example is discussed in more detail later.
1.2. Sampling from the tails
Random measurement error is well-nigh inevitable, so some RTM due to it is guaranteed in most circumstances. However, in addition to random error, there are often other, more systematic influences that aren’t preserved from one measurement occasion to another, resulting in stronger RTM than is expected based on random error alone. In other words, variables may naturally show instability in their true, non-error values over time. If you are measured at a time when you are at your highest or lowest level (that is, close to the tails of the distribution) of such a variable, you are likely to regress to a more average value when remeasured.
For example, if you recruit patients suffering from depression for a clinical trial and measure their level of depression at the start of the treatment and at the end, you are likely to see them get better even if the treatment offered is completely ineffectual. This is because a disorder like depression is often episodic, with symptoms worsening and improving spontaneously over time. As patients usually seek treatment when their condition is at its worst, the mere passage of time often leads to some recovery regardless of any treatment. RTM in this case may happen not because of measurement error but because spontaneous improvement following a severe phase of the disease is a part of the normal course of the disease. Without a control group that doesn’t receive the treatment, you can never tell for sure if a patient would have got better untreated as well.
The following table (from Campbell & Kenny, 1999, p. 47) shows how the depression severity of patients assigned to no-treatment control groups in 19 clinical trials changed over the course of the trials. (Depression was measured using questionnaires like the Beck Depression Inventory.)
Table 1.
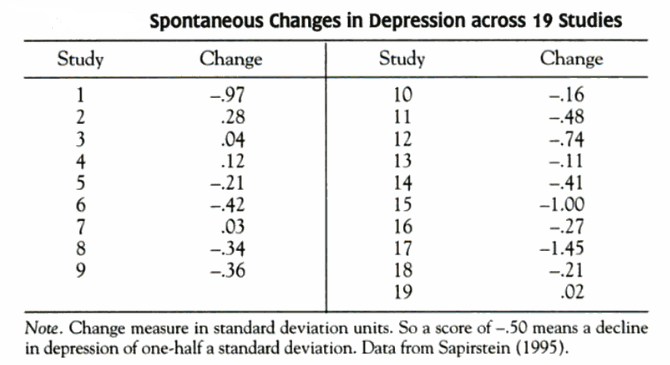
While there was variability between studies, depression levels decreased in 14 out of 19 studies for a mean decline of 0.35 standard deviation units. Most studies therefore saw RTM as untreated patients spontaneously got better.
1.3. Stable but nontransmissible influences
There are also variables that are temporally stable per se but nevertheless show RTM under certain conditions. The classic example of this is genetic transmission of traits in families. The graph below is from Galton (1886), which is a foundational study of RTM. Galton plotted the heights of mid-parents (that is, the average heights of spouses) against the heights of their children. He found that the children of very tall parents were shorter than them, while the children of very short parents were taller than them, on the average.
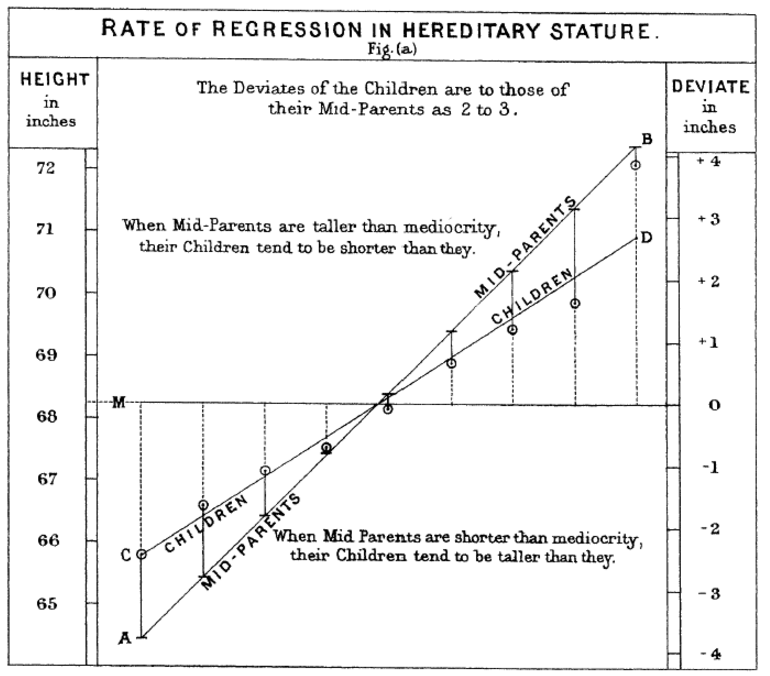
Figure 2.
Given that height is easy to measure accurately, random measurement error is rarely a major cause of RTM for height. The real explanation is that, as a general rule, parents can only transmit their additive genetic effects to their children. Other influences on parents’ own traits, such as non-additive genetic effects and accidents of individual development (e.g., a severe illness contracted early in life), will usually not be transmitted to children for lack of reliable mechanisms for such transmission. If parents have extreme phenotypic values due to other influences than additive genetic ones, those influences cannot be transmitted to their children who therefore tend to be phenotypically less extreme (more average) than their parents.
* * * *
In what follows, I will mostly employ the classical psychometric true score theory and random measurement error (case 1 above) to elucidate RTM, but I’ll also consider situations where RTM happens because of sampling from the tails (case 2) or because there are no mechanisms for transmitting otherwise stable influences (case 3).
2. Measurement error and true score theory
I’ll start by discussing the kind of RTM that is due to random measurement error. This is easiest to do from the perspective of true score theory. This theory is very general, so the variable of interest may be just about anything. It could be an IQ score, a measure of socioeconomic status, a blood pressure reading, whatever. However, I’ll be mostly using IQ in my examples because of its familiarity.
In true score theory, an individual’s measured value X for some variable of interest is modeled in terms of T, the true score, and E, the error score. X, called the observed score, is the sum of the two other variables:
X = T + E
In this equation, T represents a stable component that is reliably reproduced whenever the variable is measured. It could be, say, an individual’s underlying level of intelligence, if the variable in question is IQ.
In contrast to the stable and reliable true score, E is a random error component that is correlated neither with T nor with any new E component that is obtained if the variable is remeasured. In the case of IQ, E represents a conglomeration of ephemeral influences that may either boost (e.g., lucky guessing in a multiple-choice test) or impair (e.g., fatigue during test) your performance on one test occasion but will be absent and replaced with other influences if you retake the test. E can be thought of as noise that can prevent the observed score from accurately reflecting your true score. The smaller the influence of E on observed test scores is, the more reliable the test is. If error scores for all individuals were zero, the test would be perfectly reliable, and observed scores would be equal to true scores—something that is very rarely accomplished.
I will assume that both T and E are normally distributed and that E has a mean of 0 in the population. The normality of error scores may be violated in real-life data sets, but because the assumption is at least approximately true in many situations and it would be such a hassle for me to assume otherwise, I’ll ignore problems arising from non-normal error score distributions.
2.1. Example: Donald’s IQ
Let’s say we have a man, call him Donald, who takes an IQ test and gets a score of 125. This is his observed score in the test. In practice, the observed score is the only one of the three variables (X, T, E) introduced whose exact value can be known. The other two are hidden or latent variables whose values may only be estimated in various ways. But let’s assume that we somehow knew Donald’s true score and error score values to be T = 115 and E = 10. It can be readily seen that the observed score X equals 125 because X = T + E = 115 + 10 = 125.
If Donald were to retake an IQ test, what would be the best bet for his retest score? As T is the same (=115) across measurement occasions, the new observed score will be determined by E. Because error scores are uncorrelated with both true scores and previous error scores and normally distributed with a mean of 0, our best guess for Donald’s error score in the second test is 0, as it is the most common error score value. Therefore, the expected observed score in the second test is 115 + 0 = 115. If that happens, we have seen regression towards the population mean (which is 100 in the case of IQ)—an IQ of 125 shrunk to 115 upon retesting. The reason for the regression would be that only the reliable component (T=115) gets reproduced upon retesting, whereas the previously strongly positive error score (=10) is not reproduced because it does not represent a reliable, repeatable influence on IQ scores.
Of course, Donald’s error score in the second test may not be 0, but it is very likely that it is less than the original error score of 10 because error scores are normally distributed with a mean of zero, meaning that there’s a 50% chance that the error score is less than 0 and an even greater chance that it is less than 10. Given that Donald had an error score in the first test that took him further from the population mean than his true score is, RTM is to be expected in a retest.
As the example shows, people in fact regress towards their own true scores rather than towards the mean score of the population or sample. However, because true scores are unknowable quantities—in reality, we can’t really know Donald’s or anyone else’s true score—we have to settle for estimating what will happen on average, and on average people regress towards the mean because most people have true scores nearer to the mean than their observed scores are, as discussed in more detail later. Some people, of course, may not regress at all—they may get the same observed scores in two tests, or they may be further from the mean and/or from their true score in the second test—but on average RTM is what happens.
3. Simulation: 10,000 IQ scores
For a more involved look at how RTM happens in a large group of people, I generated simulated IQ scores for 10,000 individuals drawn from a population with a mean IQ of 100 and a standard deviation (SD) of 15. I chose a reliability of 0.80 for these scores. This means simply that 80% of the between-individual differences in the scores represent reliable, or true score (T), differences, while 20% of the between-individual differences are due to random measurement error (E).
The variance of the observed IQ scores is the square of their SD, or 15^2 = 225. Of this total variance, 80% or 180 is true score variance. The rest, 45, represents error score variance. By taking square roots of these variance components we get the SDs of the true scores and the error scores: √180 ≈ 13.42 and √45 ≈ 6.71, respectively.[Note] The SD of the error scores can be used to construct confidence intervals for the observed scores. With an SD of 6.71, the 95% confidence interval is ±1.96 * 6.71 ≈ ±13.5. Therefore, the observed IQs of 95% of test-takers will be within 13.5 points (in either direction) from their true scores.
To fully characterize the (normal) distributions of error scores and true scores, we need to know the means of each distribution. For error scores, it is 0, because negative and positive errors are equally likely, canceling each other for the average individual. The mean of the true scores is 100. This is so by my choice, but because 100 is the mean and thus the most common true score and 0 is the mean and thus the most common error score, the mean of the observed score distribution is necessarily 100 + 0 = 100, within the limits of sampling error.[Note]
Knowing the means and SDs of the true scores (100, 13.42) and the error scores (0, 6.71), we can get numbers matching these parameters from a random number generator and graph the resulting distributions, as shown in Figures 3 and 4:
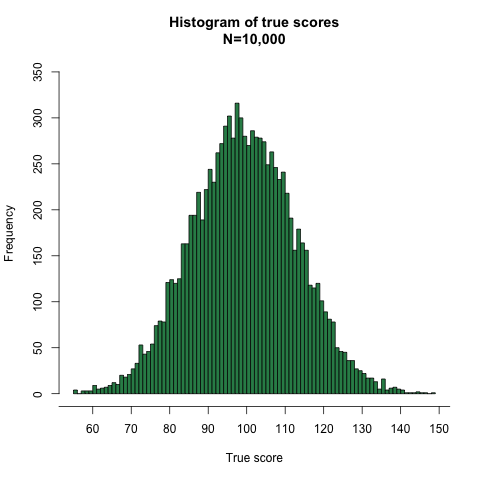 Figure 3.
Figure 3.
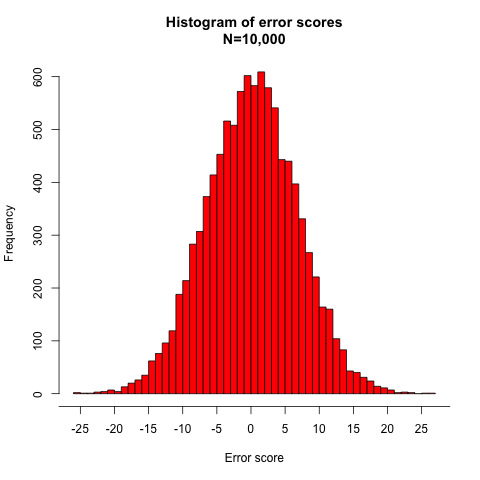
Figure 4.
(The R code for all of my graphs, simulations, and analyses is available in the Appendix.)
True scores are expected to be uncorrelated with error scores. We can verify this by correlating the simulated true and error scores, which produces a Pearson correlation of 0.001 (p=0.92). Error and true scores are not associated beyond chance levels. This is, of course, expected because the two variables were randomly generated.
The observed IQ scores were formed simply by summing the 10,000 true scores and 10,000 error scores: X = T + E. This gives the following distribution of 10,000 observed IQ scores with a mean of 100 and an SD of 15:

Figure 5.
Now that we have one set of IQ scores, we can simulate what would happen if the same 10,000 individuals took another IQ test. In the new test, the true score for each individual stays the same, but everyone gets a new error score generated randomly from a distribution that has, as before, a mean of 0 and an SD of 6.71. The results are plotted in Figure 6, with the gray dots representing test scores. On the x-axis we have the scores from the first test while the retest results are on the y-axis.
Figure 6.
The red line is the least squares fit line that best predicts scores in the second test based on scores in the first test. The slope of the line (its steepness) is 0.80.[Note] The regression equation for the red line gives the expected score in the retest, E(Xretest), for someone who scored X in the first test:
E(Xretest) = 20 + 0.8 * X
The blue lines with arrows in the graph highlight the degree of regression for selected observed scores. Those who scored 60 in the first test score 68, on average, in the second test, while those who scored 80 in the first test average 84 in the second. The blue lines also highlight two above-average scores in the first test, 120 and 140, and it can be seen that people who scored above average regress to the mean in a symmetrical fashion to those who scored below the mean. Notably, those scoring 60 or 140 in the first test experience more RTM than those who scored 80 or 120—the regression effect is stronger for more extreme scores. As to individuals whose scores in the first test were equal to the mean IQ of 100, they cannot, as a group, experience RTM, so they average 100 in the second test, too.
So, why does RTM happen for these simulated individuals? Let’s look again at the true scores and error scores that compose the observed scores:
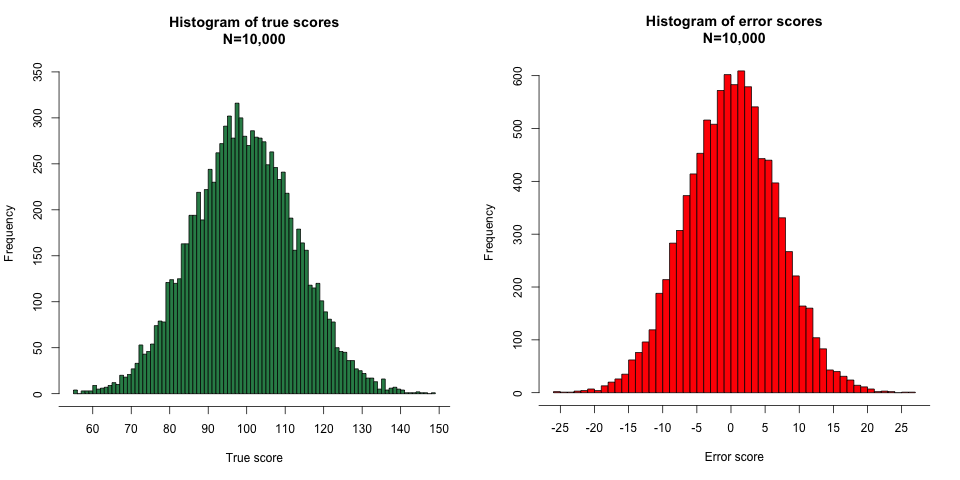
Figure 7.
In the first test, each individual has a true score (left-hand distribution in Figure 7) which is summed with a randomly selected error score from the error score distribution (right-hand distribution).Let’s say that you have a true score of 110 and get an error score of +20 in a test, resulting in an observed score of 130. In a normal distribution with a mean of 0 and an SD of 6.71, such an error score is 20/6.71 ≈ 3 SDs above the mean, corresponding to 99.9th percentile. Therefore, 999 out of 1000 people get smaller error scores than 20 in the test.
Now, if you retake the test, what’s the probability that you get a new error score that is smaller than 20? Because error scores are uncorrelated across tests, the probability of your getting a particular error score is the same as any person getting a particular error score, so your probability of getting an error score smaller than 20 is 99.9%. This means that you will almost certainly get a lower observed score in the retest, causing you to regress towards the population mean. Most likely, your error score will be within a handful of points from 0, given that 68% of error scores are within ±1 SD of the mean error score of 0, which in this case means between -6.71 and +6.71.
But what if your true score is, say, 70, and you get an error score of 20, for an observed IQ of 90? Will you regress towards 100 when retested? You probably will not. On the contrary, you will likely be further away from the mean in the second test, given that you’ll almost certainly get an error score smaller than 20. This underscores the fact that, firstly, RTM happens only on average. There are more people with true scores close to the mean than far from the mean, so on average people with large error scores tend to regress towards the mean when retested. Secondly, individuals actually regress towards their own true scores rather than the true score of the population or sample. The true scores of individuals, however, are unknown, whereas the mean true score is known (it is the same as the observed mean), so we use the mean to describe how RTM occurs for the average individual, because what happens to a particular individual in a retest cannot be predicted.
Another way to make RTM more transparent is to examine how individuals with a particular observed score regress in a retest. Table 2 shows everybody (N=31) from the simulation who scored 130 in the first test, along with their retest scores, error scores in both tests, and true scores.
| ID # | Observed score 1 | Observed score 2 | Error score 1 | Error score 2 | True score |
|---|---|---|---|---|---|
| 1 | 130 | 138 | -5.6 | 2.5 | 136 |
| 2 | 130 | 114 | 13.8 | -2.4 | 116 |
| 3 | 130 | 120 | 10.5 | 0.6 | 119 |
| 4 | 130 | 134 | -3.9 | -0.3 | 134 |
| 5 | 130 | 113 | 16.2 | -0.8 | 114 |
| 6 | 130 | 120 | -1.5 | -10.7 | 131 |
| 7 | 130 | 128 | 6.6 | 4.7 | 123 |
| 8 | 130 | 127 | 9.7 | 6.8 | 120 |
| 9 | 130 | 140 | -1.8 | 7.7 | 132 |
| 10 | 130 | 127 | 9 | 5.6 | 121 |
| 11 | 130 | 130 | 1.6 | 2.1 | 128 |
| 12 | 130 | 106 | 23.2 | -1.5 | 107 |
| 13 | 130 | 125 | 5.2 | -0.4 | 125 |
| 14 | 130 | 124 | 7.3 | 0.5 | 123 |
| 15 | 130 | 128 | 7.4 | 4.5 | 123 |
| 16 | 130 | 122 | 13.1 | 4.9 | 117 |
| 17 | 130 | 122 | 4.4 | -3.8 | 126 |
| 18 | 130 | 134 | 5 | 9.3 | 125 |
| 19 | 130 | 120 | 9.9 | -0.4 | 120 |
| 20 | 130 | 143 | 1.8 | 15.4 | 128 |
| 21 | 130 | 127 | 4.7 | 1.7 | 125 |
| 22 | 130 | 112 | 8.3 | -10.4 | 122 |
| 23 | 130 | 122 | 3.4 | -5.5 | 127 |
| 24 | 130 | 114 | 5.6 | -10.2 | 124 |
| 25 | 130 | 120 | 1.2 | -8.6 | 129 |
| 26 | 130 | 113 | 5.7 | -11 | 124 |
| 27 | 130 | 124 | 0.8 | -4.9 | 129 |
| 28 | 130 | 105 | 4.1 | -21.4 | 126 |
| 29 | 130 | 123 | 6.9 | 0.1 | 123 |
| 30 | 130 | 130 | 7.2 | 6.6 | 123 |
| 31 | 130 | 127 | 7.4 | 3.6 | 123 |
| Mean | 130 | 124 | 6.0 | -0.5 | 124 |
The last row of the table shows the mean values of each variable. Those who scored 130 in the first test tend to regress towards the mean, scoring an average of 124 in the retest. The mean error score in the first test was 6.0 points, while it’s about 0 in the retest (-0.5 to be precise). The mean retest error score is ~0 because 0 is the expected, or mean, error score that any group of people who are retested are going to converge on, regardless of their original scores. Because the mean retest error is ~0, the mean observed retest score is approximately equal to the mean true score.
The fact that the retest and true scores both average 124 does not mean that the mean error score of all people scoring 124 in the retest is ~0. Instead, the mean error score of all people scoring 124 is about +5, reflecting the fact that people getting observed scores above the population mean tend to have positive error scores. Only the subset of people who regressed from 130 to an average of 124 have a mean error score of ~0.
4. Why is RTM stronger for more extreme scores?
Error scores are uncorrelated with true scores. At every level of true scores, error scores are normally distributed with a mean of zero. In the IQ simulation, for example, whether your true score is 70 or 100 or 130, your error score is in any case drawn from a normal distribution with a mean of 0 and an SD of 6.71 points.[Note] Table 3 shows the means and SDs of error scores for selected true scores in the simulated data.
| True score | Mean error | SD of error | N |
|---|---|---|---|
| 60 | 2.4 | 11.51 | 3 |
| 70 | -0.4 | 6.69 | 21 |
| 80 | 0.1 | 6.81 | 121 |
| 90 | 0.5 | 6.61 | 222 |
| 100 | 0.6 | 6.73 | 280 |
| 110 | -0.7 | 6.69 | 241 |
| 120 | 0.7 | 6.57 | 101 |
| 130 | -2 | 7.13 | 25 |
| 140 | 0.7 | 5.18 | 5 |
Given that large errors (either positive or negative) are not more common among those with extreme true score values (except by chance), how is it possible that measurement error and therefore regression toward the mean especially affect scores that are located farther from the mean, at the tails of the distribution? Wouldn’t you expect negative and positive errors to cancel out at each true score level? Why does RTM happen at all if negative and positive error scores are balanced so that the average error is 0 across the board?
The answer to these questions is that while measurement error is uncorrelated with true scores, it is correlated with observed scores. This follows directly from the definition of observed scores. For example, if the reliability of a test is 0.80, it means that 20% of the variance of the observed scores is accounted for by measurement error. The correlation of error scores with observed scores is then √0.20 ~ 0.45—that is, small observed scores (e.g., IQ=70) tend to be associated with negative error scores, and large observed scores (e.g., IQ=130) with positive error scores. To put it another way, in the same sense that observed scores would be perfectly correlated with true scores save for the influence of error scores, observed scores would be perfectly correlated with error scores save for the influence of true scores. Table 4 shows the means and SDs of error scores for selected observed scores in the simulated IQ data.
Table 4.
| Observed score | Mean error | SD of error | N |
|---|---|---|---|
| 60 | -12.9 | 8.3 | 9 |
| 70 | -7 | 6.71 | 52 |
| 80 | -4 | 6.33 | 111 |
| 90 | -1.2 | 5.85 | 254 |
| 100 | -0.1 | 6.25 | 283 |
| 110 | 2.4 | 5.92 | 241 |
| 120 | 3.8 | 6.42 | 131 |
| 130 | 6 | 5.88 | 31 |
| 140 | 9.8 | 5.01 | 13 |
The smaller an observed score is, the more likely it is that its smallness is in part due to a negative error score. Conversely, the larger an observed score, the more likely it is that it is influenced by a positive error score. Plotting all observed scores against their associated error scores (Figure 8) makes the linear relation between the two apparent. Given that the correlation is ∼0.45, the scatter around the fit line is quite large but it is of similar magnitude across the range of observed score values.
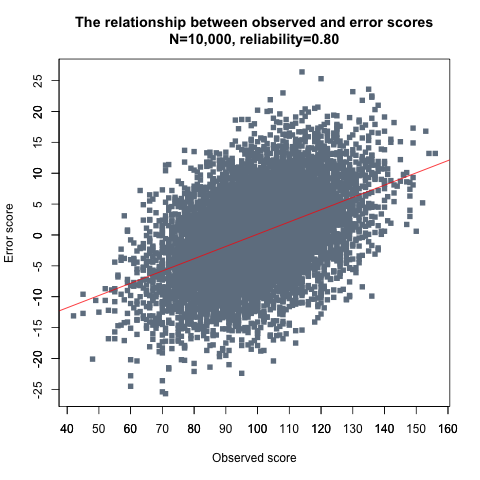
Figure 8.
This idea is perhaps not obvious, so I’ll try to explain it in a more intuitive way. With normally distributed true scores and error scores, there are more true scores than observed scores nearer to the population mean. This can be seen in the following graph where the distributions of the true and observed scores from the simulated example are superimposed:
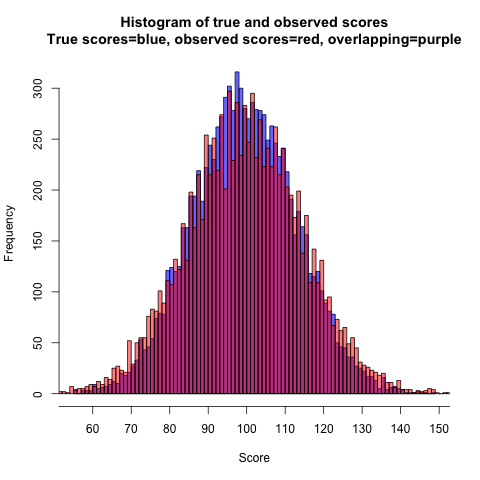
Figure 9.
The observed score distribution is broader and flatter than the true score distribution. There are comparatively fewer individuals with observed scores at the mean and more at the tails. When error scores are paired with true scores to form observed scores, true scores get, in a sense, pulled away from the mean because they “hang together” with their associated observed scores. Error scores are correlated with observed scores, with negative errors becoming more prevalent as you move from the mean towards smaller observed scores, and positive errors becoming more prevalent in the other direction from the mean.
For example, let’s say someone gets an observed IQ score of 80 in a population with a mean score of 100. Is his or her true score more likely to be smaller than 80 or larger than 80? The answer is that it’s probably >80 because there are more people with true scores in the range of, say, 80–90 who have negative error scores than there are people with true scores in the range of 70–80 with positive error scores—this is simply because of the shape of the normal distribution. To be precise, in a normal distribution of true scores with a mean 100 and an SD of 13.42[Note], 5.5% of scores are in the range of 70–80 while 16% are in the range of 80–90, corresponding to a ratio of 16/5.5 ~ 2.9. Given that true scores within each of these ranges are equally likely to be accompanied with negative and positive error scores, an observed score of 80 is more likely to be the sum of a true score of, say, 83 and an error score of -3 than it is to be due to a true score of 77 and an error score of +3—this is simply because there are more people with true scores of 83 than 77. When the individual who first scored 80 retakes the test, his or her new observed score is likely to be >80 because the underlying true score is likely to be >80 while the expected error score is 0—hence, regression towards the mean. This is so despite the fact that people with actual true scores of 80 are equally likely to have negative and positive error scores.
RTM gets weaker the closer you get to the population mean. This is because, as you approach the mean of the distribution, the number of true scores at each side of the observed score gets more even. For example, let’s say we have people with observed IQs of 90, the reliability still being 0.80. As noted, 16% of people have true scores in the range of 80–90. The proportion of true scores in the range of 90–100 is larger, 27%. The ratio of larger true scores to smaller true scores around the observed score of 90 is 1.7, compared to the ratio 2.9 around the observed score of 80. This means that RTM will be smaller for those scoring 90 compared to those scoring 80.
Finally, those scoring 100 in the first test will average 100 in the retest, experiencing no regression. This is because the number of true scores at either side of 100 is the same, meaning that an observed score of 100 is equally likely to result from a true score that is below 100 as from a true score than is above 100. Among those with observed scores of 100, those with true scores below 100 will likely score below 100 in a retest, while the opposite is true for those with true scores above 100. Thus, on average, there is no discernible RTM for those scoring 100.
To recap, RTM due to measurement error is caused by the fact that people with large (absolute) error scores on first measurement tend to have small (absolute) error scores on second measurement. Because small error scores are more common and error scores are uncorrelated across measurement occasions, most people will get small error scores upon remeasurement even if they got large scores the first time around.
People with extreme—positive or negative—observed scores tend to regress more toward the mean than people with less extreme observed scores. This happens because error scores are correlated with observed scores: large negative errors are common among those with very small observed scores, while large positive error scores are common among those with very large observed scores. RTM disproportionately affects extreme observed scores to the extent that they are caused by extreme error scores. In contrast, extreme observed scores that are caused by extreme true scores are not affected by RTM.
If mean, reliability and the SDs of observed and error scores are known, the average amount of RTM that people scoring X will experience in a retest can be predicted. If we assume that…
X = 130 mean = 100 reliability = 0.80 SDobserved = 15 SDerror = 6.71
… we can predict that the average amount of RTM will be about 6 points. This is because the correlation between observed and error scores is √0.20 ≈ 0.45, causing those with observed scores two SDs above the mean (=130) to have a mean error score of 0.45*2*6.71 ≈ 6. Because the expected error score in the retest is 0, the mean RTM effect will be 6 points, and people will regress from 130 to an average score of 124. The fact that the average amount of RTM is predictable for a given observed score can be exploited to compute so-called true score estimates, as discussed later.
5. Why RTM does not decrease variability: Egression from the mean
RTM causes extreme values of a variable to be less extreme when remeasured. You might therefore expect the variable to be less dispersed on the second measurement, with more values nearer to the mean and fewer at the tails. In fact, RTM does not lead to diminished variance. In my IQ simulation, for example, the variance is the same (15^2 = 225) on both testing occasions.
If the causal factors that generate variability do not change, variance will not change across measurement occasions. In my simulation, 80% of individual differences in IQ scores are due to true score differences and 20% due to error score differences whenever IQ is measured. This means that while people who got extreme scores in the first test will tend to be less extreme in the second test, other people will take those “available” extreme scores in the second test. Those other people can for the most part only come from among those who were less extreme in the first test. This means that RTM is accompanied by a countervailing phenomenon which could be called egression from the mean (‘egress’: to come or go out, to emerge).
Egression from the mean can be demonstrated using my simulated IQ data. In the graph below, the results from the second test are now on the x-axis while the results from the first test are on the y-axis. The arrowed blue lines highlight how people who got selected scores in the second test had scored in the first test.
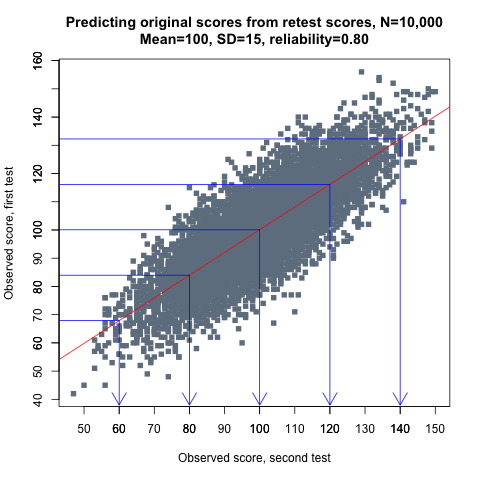
Figure 10.
This graph, with its time-reversed variable order, looks like a mirror image of the one presented earlier. The farther from the mean people scored in the retest, the more they egressed from the mean compared to their score in the first test, on average. For example, those who scored 60 in the retest had originally scored about 68, on average. Most people who scored around 68 in the first test didn’t egress to 60, of course—there are more people scoring 68 than 60 on every testing occasion, for one thing—but a subset of them did.
The egression effect is caused by people getting a more extreme (negative or positive) error score on remeasurement than originally. Given that error scores are “memoryless” in the sense that they are uncorrelated across measurement occasions, how is it possible that those with less extreme error scores on first measurement are more likely to get more extreme error scores when remeasured? In fact, they aren’t. The probability of extreme error scores is the same for everybody. Those who get extreme error scores and egress from the mean when remeasured tend to be drawn from among people who were originally closer to the mean for the simple reason that there are more people closer to the mean.
The egression effect is of the same magnitude but opposite to the regression effect. Egression effectively undoes RTM every time, maintaining the variance that exists. The complementarity of regression and egression underscores the fact that they are not forces for producing permanent change in a variable. Instead, regression and egression are ways to describe how the impact of transitory influences shifts from one group of people to another group of people. Regression and egression occur because there are temporary influences that impact different people over time.
As long as the population distribution of the variable does not change over time, RTM is always accompanied by egression from the mean. When a sample consists of individuals sampled from the tail(s) of the distribution—as in the case of depression patients described earlier—there appears to be no egression, but this is an artifact of selection bias. If the sampling frame of the study was, say, everybody who had an episode of depression during the last 12 months, rather than just people who recently sought treatment for depression, egression from the mean (i.e., people getting more depressed) would be observed and it would be equal in magnitude to RTM. The only way for this to not happen would be if the population prevalence of depression changed during the course of the study (because of, for example, new and more effective treatments).
Given that both regression and egression always happen, you might ask why RTM gets so much more attention. One reason is that many studies sample individuals from the extremes of the distribution—medical research focuses on sick rather than well people, psychologists like to study low-performing or high-performing people rather than average people, sociologists and economists are more interested in the poor and the rich rather than the middle class, and so on. This means that the samples studied will be, over time, strongly influenced by RTM while the effect of egression will be small.
Another reason for the focus on RTM is that egression introduces more error or other transitory influences on observed scores, whereas regression reduces unreliability, bringing the observed values closer to the stable underlying values.
6. Estimating true scores
The knowledge that observed scores tend to regress towards the mean makes it possible to predict what would happen if we obtained another set of observed scores for the same individuals even if no actual remeasurement takes place. Truman Kelley, who was an influential early psychometrician, introduced true score estimation for this purpose (see Kelley, 1923, p. 214ff, and Kelley 1927, p. 178ff; several of his books can be downloaded here). Kelley’s true score estimates, T’, are calculated in the following manner:
T' = M + ρ * (X - M)
where M is the population or sample mean, ρ is reliability, and X is the observed score. The purpose of this formula is to obtain scores that are closer to the true values than the observed scores are. It calculates how much a given observed score is expected to regress if remeasured, based on the known mean and reliability values, and assigns the expected regressed score as the best estimate of the true score. For example, if your observed IQ score is 130, the mean is 100, and the test’s reliability is 0.80, your estimated true score is T’ = 100 + 0.8 * (130 – 100) = 124.
An equivalent way of writing Kelley’s formula is:
T' = ρ * X + (1 - ρ) * M
This version of the equation makes it more explicit that the true score estimate is a weighted composite of the observed score (X) and the mean (M), with reliability ρ and 1 – ρ as weights. If we had a test that was completely unreliable, consisting of 100% measurement error, the estimated true score would be 0 * X + (1-0) * M = M. That is, if the test is just noise, with a reliability of 0, the best estimate for the individual’s true score is simply the population mean because it’s the only piece of information we have; the observed score is ignored because given a reliability of 0 it contains no information.
At the other end, if the test’s reliability is 1, the estimated true score is 1 * X + (1 – 1) * M = X. In other words, the estimated true score equals the observed score because an observed score in a perfectly reliable test equals the true score. In this case, the equation ignores the population mean value because we already get all the information we need from the observed score.
In practice, the reliability of a test is likely to be higher than 0 and lower than 1. For example, if the reliability is 0.50—that is, 50% of individual differences in observed scores are due to true score differences and 50% due to measurement error—the equation weighs the observed and mean scores equally, “pulling” the observed score half-way towards the mean—for example, the true score estimate for an IQ score of 130 would be 115. In contrast, if the reliability is, say, 0.90, the observed score will be pulled towards the mean by only 10% of the distance between the observed score and the population mean—for example, from 130 to 127.
In practice, estimated true scores are rarely used. Arthur Jensen and some other researchers in the same intellectual territory are the only ones I know of to have frequently used Kelley’s method in recent decades.
One reason for not using true score estimates is that they make group differences larger, as discussed below. Another reason might be that it’s not always clear what the relevant population mean score is. For example, let’s say we have a white person who scores 130 in an IQ test with a middling reliability of 0.80. If the white mean is 100, the true score estimate is 124. However, if the white person is Jewish, the true score estimate might be 126 instead, given a Jewish mean IQ of 110. In a stringent selection situation (for a school, job, etc.) those couple of points could make all the difference, making the choice of population mean very consequential.
A more technical or philosophical argument against Kelley’s formula is that it is a biased estimator. This means that the sampling distribution of estimated true scores is not centered on the actual true score. In other words, if you have a number of observed scores for an individual and you use Kelley’s method to estimate true scores for each observed score, the mean of those estimates is probably not equal to the individual’s true score (unless X = M). In contrast, the mean of the observed scores is centered on the true score, and if you have a number of observed scores (from parallel tests) for an individual, you can be confident that their mean is equal to the true score, within the limits of sampling error (that is, observed scores are unbiased).
Given that estimated true scores are biased in this way, why then prefer them over observed scores? The answer is that an estimated true score is, on the average, closer to the true score than an observed score is.[Note] This is because considering the mean of the population from which the individual is drawn together with his or her observed score effectively increases the reliability of the score. In my simulated IQ data the mean absolute error score for observed scores is 5.3 while it’s 4.8 for true score estimates. The advantage of true score estimates gets larger if we look at extreme scores. For example, when only considering those with observed scores below 80 or above 120 in the simulation, the mean absolute error score is 6.8 for observed scores, while it’s 4.7 for true score estimates. Furthermore, the more unreliable a variable is, the more can be gained by using true score estimates.
Because true scores estimates are linear transformations of observed scores, they correlate perfectly with the observed scores and therefore correlate with other variables just like the original, untransformed variable does. For this reason, if the purpose is not to interpret the scores on the original scale but to just rank individuals or to correlate the variable with other variables, nothing is gained by using true score estimates. However, true score estimates have an important function when groups with different mean levels for a variable are compared, as discussed later.
7. Will RTM go on forever?
So far, I’ve only examined situations where there are two measurements or tests. But what would happen if there were three or more sets of measurements of the same individuals? Would RTM go on and on, with individuals getting closer and closer to the mean with each measurement? As is obvious from the foregoing, that would not happen. For a given group of individuals, RTM is a one-off phenomenon, and it does not alter the population-level distributions of variables over time. If we select a group of individuals who obtained an extreme score when first measured, they will regress towards the mean when remeasured. If they are remeasured again, the statistical expectation is that they will, as a group, neither regress nor egress but stay where they were on the second measurement—and this will be true no matter how many times they are remeasured. This is because the expected error score for this group is always 0 after the first measurement; on the first measurement the expected error score was non-zero because by selecting individuals with extreme observed scores you essentially select individuals who have non-zero error scores.[Note]
It should be clarified that the idea of parallel tests, at least in the case of IQ, is more of a thought experiment than a model that you would expect to closely fit data from repeated tests. This is so because by taking a test people learn to be somewhat better at it, which means that their average score will be somewhat higher in a retest. However, often we have scores only from a single test administration, in which case the parallel test model offers a convenient way of thinking about how measurement error has affected those scores. Moreover, if there’s a reasonably long time interval—say, a year—between two test administrations, practice effects are expected to be very small. (On the other hand, if the interval is several years, we would expect individuals’ true scores to change in accordance with the well-known age trajectories in cognitive ability [e.g., Verhaeghen & Salthouse, 1997]. Even in that case, however, we would not expect the rank-order of individuals to change much.)
8. Kelley’s paradox, or why unbiased measurement does not lead to unbiased prediction
Let’s say you have two groups, and that after measuring some variable of interest X you find that the groups differ in their mean values for X. If you then remeasure X, people who previously got extreme values will now tend to get less extreme values because of measurement error and RTM. However, because individuals regress towards the mean value of the group they belong to (rather than towards some common grand mean), the expected amount of regression will depend on a given individual’s group membership. The upshot of this is that members of different groups who got similar values on first measurement will tend to get systematically different values on second measurement. Specifically, members of the group with a higher mean score will tend to get higher values than members of the other group. This is because a given observed score will tend to overestimate the true score of a member of the lower-scoring group when compared to a member of the higher-scoring group.
The fact that RTM occurs towards population-specific mean values leads to problems in situations where groups are compared. For example, many studies have investigated whether cognitive ability tests predict the school or job performance of white and black Americans in the same way. There’s long been concern that tests might be biased against blacks, resulting in fewer of them being admitted to selective colleges or hired by firms than would be fair given their abilities. However, the standard finding from studies on predictive bias is that to the extent that there is bias, it favors blacks: they tend to score lower on criterion measures, such as college grade-point averages and job performance evaluations, than whites who have identical IQ, SAT, or other such ability scores. This is in fact exactly what you would expect if both the tests and the criterion variables were internally unbiased with respect to race in the specific sense that psychometricians usually define internal bias.
This paradoxical phenomenon where internally unbiased tests and criterion measures lead to external bias, or biased prediction, was dubbed Kelley’s paradox by Wainer (2000). The name was chosen because the aforementioned Truman Kelley was the first to discuss how group mean values contain information that is not included in (unreliable) observed scores.[Note]
8.1. Simulation: Black-white IQ gap
I will next show through simulations how Kelley’s paradox works in the context of the black-white IQ gap. For white scores, I will use the same 10,000 IQ scores from before, with a mean of 100, an SD of 15, and a reliability of 0.80. For black scores, the SD and the reliability are 15 and 0.80, too, but the mean is 85, in accordance with the IQ gap that is usually observed between whites and blacks in America. Figure 11 shows the regressions of observed scores on true scores in the simulated blacks and whites.
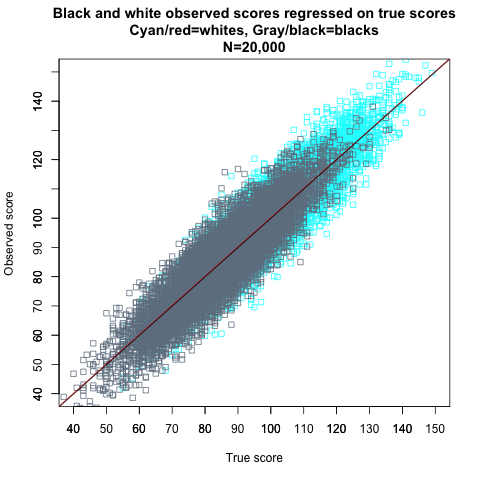
Figure 11.
The regressions are the same—the regression lines have the same slopes and intercepts—and therefore whites and blacks with the same true scores have the same observed scores, on average, with only random measurement error causing differences between individuals matched on true scores. This is in fact exactly the definition of strict measurement invariance, which is the term used when a test is internally unbiased with respect to particular groups, measuring the same construct (such as general intelligence) in the same way across groups. With strict invariance, the distribution of observed scores is identical for members of different groups who have the same true scores; everyone with the same true score gets the same observed score, within the limits of random measurement error (whose variance is the same across races).[Note] For example, if we choose all whites and all blacks with true scores of 115, both groups have a mean observed score of 115 and the same symmetrical dispersion around that mean due to measurement error.
Most people would probably agree that strict invariance is a reasonable indicator of a test’s internal unbiasedness, and that the IQs of my simulated blacks and whites are therefore “measured” without bias. However, if groups differ in their mean true scores, the following paradox arises even if strict invariance holds: Members of different groups with the same observed scores do not have the same distribution of true scores. If the population means differ, so will the regressions of true scores on observed scores. This can be demonstrated by flipping the variables from Figure 11 around (the red and black lines are the best-fit lines for whites and blacks, respectively):
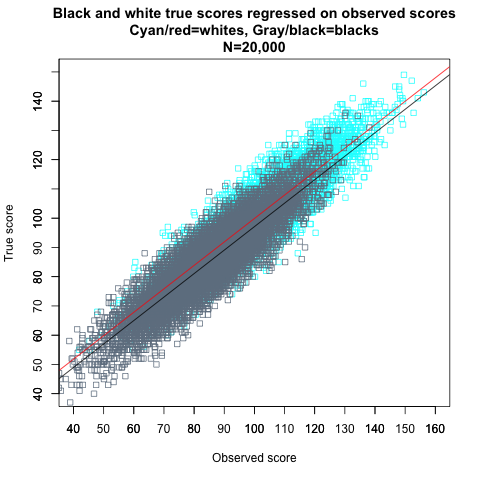
Figure 12.
In this scatterplot, observed scores for blacks and whites are used to predict their true scores. It can be seen that the slope coefficient (which indicates the “steepness” of the regression line) does not differ between groups—any change in observed scores results in the same amount of change in true scores in blacks and whites. However, it can also be seen that the intercepts—the locations where the regression lines intersect with the Y axis—differ between the races. The intercept difference indicates that the expected true score (Y axis) for any given observed score (X axis) is larger in whites than blacks.
From the regressions, we get the following equations for expected true score values, E(T), for whites and blacks at each level of the observed score X:
E(Twhites) = 20 + 0.80 * X E(Tblacks) = 17 + 0.80 * X
At every IQ level, the underlying average true score for blacks is three points lower than that for whites. For example, if we choose all whites and all blacks with observed scores of 115, the mean true score of the white group will be 20 + 0.8 * 115 = 112, while the mean true score of the black group will be 17 + 0.8 * 115 = 109. This is Kelley’s paradox in action. The reason for this difference is that while the correlation between observed scores and error scores is the same, √0.20 ≈ 0.45, for both races, there’s a mean IQ difference between the two races. The expected error score for an observed score of 115 is 2 * 0.45 * 6.71 ≈ 6 for blacks, given that 115 is 2 SDs above the black mean of 85. For whites, the expected error score is 1 * 0.45 * 6.71 ≈ 3 because 115 is only 1 SD above the white mean of 100. The more extreme an observed score is, the larger its associated error score is, on the average, and an IQ of 115 is more extreme for blacks than whites. Another way to think of it is to observe that a larger proportion of whites than blacks scoring 115 have true scores that are at least that large.[Note]
Let’s say a selective college decides to grant admission to all applicants who score above 120 in an IQ test (this is not completely unrealistic considering that the SAT and the ACT are just IQ tests: Frey & Detterman, 2004; Koenig et al., 2008). Using the parameters from my simulation, we can expect that 9.1% of all whites will score above 120, while 6.8% of all whites will have true scores above 120. As for blacks, 1% are expected to score above 120, and 0.5% are expected to have true scores above 120. Therefore, roughly 6.8/9.1 ≈ 75% of whites with IQ scores above the cutoff will have true scores above the cutoff, while the same ratio is 0.5/1 = 50% for blacks. This means that even if the distributions of observed scores for those selected were the same for both races—which is unlikely—the true ability of the selected whites would still be higher than that of the selected blacks, resulting in racial differences in college performance.[Note]
Kelley’s paradox is not just a theoretical problem. It is frequently encountered in analyses of real-life data. For example, Hartigan & Wigdor (1989, p. 182) report that the intercept of the black prediction equation is lower than that for whites in 60 out of 72 studies that have examined whether the General Aptitude Test Battery (GATB) differentially predicts job performance across races. On the average, the GATB overpredicts black job performance by 0.24 SDs.[Note] Similarly, Mattern et al. (2008) report that in a sample of about 150,000 students, SAT scores overpredict first-year college GPA by 0.16 GPA points for blacks and by 0.10 GPA points for Hispanics when compared to whites. Braun & Jones (1981), Wightman & Muller (1990), and Wainer & Brown (2007) report comparable findings of pro-black and pro-non-Asian minority predictive bias based on the Graduate Management Admission Test, the Law School Admission Test, and the Medical College Admission Test, respectively. The finding is universal.[Note]
The irony of the pro-black and pro-non-Asian-minority bias that is inherent in cognitive tests given their less than 100% reliability is that the common belief is that they are biased against low-performing minorities. The “reverse” bias has long been recognized by psychometricians, but nothing has been done to address it. This is so despite the fact that the solution is simple: either use different prediction equations for each race, or use a method like Kelley’s formula to incorporate information about mean group differences in the model. Miller (1994) put it this way in his article where Kelley’s paradox is given a Bayesian interpretation:
“In plain English, once a test score has been obtained, the best ability estimate will depend on the average ability of the candidate’s group. Thus, if the goal is to select the best candidates, it will be necessary to consider group membership, and the mean ability of the candidate’s group. The general effect is to move the ability estimate for each candidate towards his group’s mean ability. When trying to select the best candidates (who will usually have evaluations above the mean for their group), the estimate for each candidate should be lowered by an amount that depends on mean and standard deviation for his group, and the estimate’s precision.”
For example, in my simulated data, transforming observed scores to true score estimates using race-specific means removes the intercept bias and therefore any overprediction that is due to measurement error, as seen in Figure 13 (compare to Figure 12).
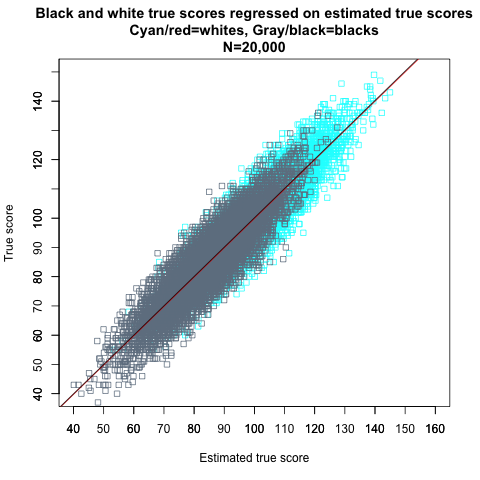
Figure 13.
The maxim that people should be treated as individuals rather than as members of groups frequently leads to unequitable treatment. For the sake of fairness, group membership should be considered together with individual characteristics wherever group differences exist. However, Linn (1984) articulated the reasons why corrections like Kelley’s formula are not used in practice:
“[I]t is not socially or politically viable to use different decision rules for members of different groups even if such a selection strategy is consistent with obtained differences in prediction systems. An important reason why this is so is that the bulk of the results of studies of differential prediction for minority and majority groups not only run counter to initial expectations and popular opinion, but they also run counter to the social goals that produced affirmative action policies. More specifically, the typical result, if interpreted within the context of the regression model, would generally require higher test scores for selection of minority group candidates than would be required of majority group candidates. Such an outcome is simply unacceptable.”
While the adoption of methods that adjust for the bias that favors low-performing groups in selection contexts is unlikely, such adjustments should nevertheless always be made in research contexts lest fallacious conclusions are drawn about discrimination. Unless a test is perfectly reliable, individuals with similar scores in it probably do not have equivalent true scores if they are drawn from populations that differ in their mean values for the variable.[Note]
8.2. Simulation: Gender pay gap
Kelley’s paradox can affect all kinds of variables, not just IQ, and it can affect several different variables simultaneously, which may produce predictive bias when methods like multiple regression analysis are used. While the biasing effect of measurement error on regression estimates is well recognized, it seems to me that the specific way in which it biases group comparisons is often not appreciated. Conceptualizing the bias in terms of Kelley’s paradox may make the phenomenon more transparent.
For example, it is well known that men earn, on the average, more money than women. It is also generally recognized that much of this gap can be explained by controlling for variables such as field of employment and hours worked. Usually such variables eliminate most of the gap, but if a residual gap remains, it is often attributed to gender-based discrimination. However, even assuming that all the relevant variables were really included in the analysis, it follows from Kelley’s paradox that the discrimination explanation is premature. Kelley’s paradox predicts that after regressing wages on all the variables that cause the gender gap there would still remain a gap, which, however, would be an artifact of measurement error.
I’ll simulate some data to demonstrate how Kelley’s paradox works with several independent variables. Let’s assume that the gender gap in weekly wages can be completely explained by four variables: hours worked, work experience, field of employment, and occupational level. For all these variables, men have higher average values than women, that is, the average man works more hours, has more work experience, is in a more remunerative field, and is more likely to be in a supervisory position, and so on, than the average woman.
Let’s say that the average weekly wages for full-time workers are 1000 dollars for men and 780 dollars for women, meaning that women earn 78 cents for every dollar men earn. Because wages are not normally distributed, I log-transform these figures, so that the average log wages are ln 1000 = 6.91 for men and ln 780 = 6.66 for women. The standard deviation for both sexes on the normally distributed log scale is, say, 0.7. These values yield the following simulated wage distributions for 10,000 men and 10,000 women:
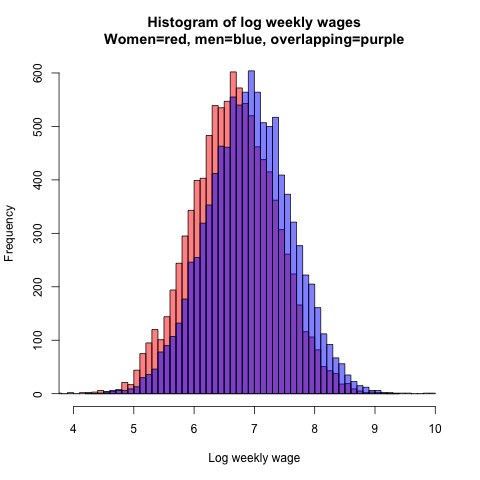
Figure 14.
Table 5 shows correlations between wages, sex, and the four simulated explanatory variables, as well as the mean values and SDs of the variables for men and women. The explanatory variables are all distributed normally with a mean of 0 (men) or -0.25 (women) and an SD of 1 within sexes. Together the four variables explain all between-sex differences in wages, as well as 50% of within-sex differences (the remaining 50% is explained by unmeasured factors, e.g., education and IQ, which are ignored here as they are assumed to be uncorrelated with sex). The four variables are uncorrelated with each other within sexes, but there’s a small correlation (0.02) between them when sexes are pooled because men tend to have higher values than women. The prefix “true” indicates that the variables are error-free true score variables.
| Gender | Log weekly wage | True hours worked | True work experience | True field of employment | True occupational level | |
|---|---|---|---|---|---|---|
| Gender | 1 | |||||
| Log weekly wage | -0.18 | 1 | ||||
| True hours worked | -0.12 | 0.37 | 1 | |||
| True experience | -0.12 | 0.37 | 0.02 | 1 | ||
| True field of employment | -0.12 | 0.37 | 0.02 | 0.02 | 1 | |
| True occupational level | -0.12 | 0.37 | 0.02 | 0.02 | 0.02 | 1 |
| Male mean | 0 | 6.91 | 0.00 | 0.00 | 0.00 | 0.00 |
| Male SD | – | 0.70 | 1.00 | 1.00 | 1.00 | 1.00 |
| Female mean | 1 | 6.66 | -0.25 | -0.25 | -0.25 | -0.25 |
| Female SD | – | 0.70 | 1.00 | 1.00 | 1.00 | 1.00 |
The last rows of the table show that women’s mean values are 0.25 lower for all variables (other than the gender dummy variable where all men=0 and all women=1). This is so because women have 6.91 – 6.66 = 0.25 lower log wages. The sex differences in the four explanatory variables were chosen so that each explains a fourth of the gender pay gap and that they together explain all of it.
For starters, I regressed log weekly wages on the gender dummy variable. The unstandardized coefficient (B) of the variable, seen in Table 6 below, is -0.25 (p<0.001). Given that the dependent variable is logarithmic, this coefficient indicates that being a woman, as opposed to a man, is associated with an expected reduction of e^-0.25-1 ≈ -22% in wages, which is the gender pay gap specified above. Sex explains 3.1% of the variance in log weekly wages, corresponding to a correlation of -0.18 between wages and sex (the correlation is negative because men, who earn more on average, are coded as 0 and women as 1).
| DV: Log weekly wage | ||||
| B | 95% CI | p | ||
| (Intercept) | 6.91 | 6.90 – 6.92 | <.001 | |
| Gender | -0.25 | -0.27 – -0.23 | <.001 | |
| Observations | 20000 | |||
| R2 / adj. R2 | .031 / .031 | |||
Next, I regressed log weekly wages on the four explanatory variables and the dummy variable indicating gender. The results can be read from Table 7 below. Each of the explanatory variables accounts for a substantial amount of wage variance. The R^2 of the model is 52%. As expected, the coefficient of the gender variable is not significantly different from zero (p=0.728). This means that the four explanatory variables account for the entire sex effect on wages; the 22% gender gap is fully explained by sex differences in hours worked, work experience, field of employment, and occupational level.[Note]
| DV: Log weekly wage | ||||
| B | 95% CI | p | ||
| (Intercept) | 6.91 | 6.90 – 6.92 | <.001 | |
| True hours worked | 0.25 | 0.24 – 0.25 | <.001 | |
| True work experience | 0.25 | 0.24 – 0.25 | <.001 | |
| True field of employment | 0.25 | 0.24 – 0.25 | <.001 | |
| True occupational level | 0.25 | 0.24 – 0.25 | <.001 | |
| Gender | -0.00 | -0.02 – 0.01 | .728 | |
| Observations | 20000 | |||
| R2 / adj. R2 | .515 / .515 | |||
As noted, the explanatory variables are “true score” variables that are not contaminated by measurement error. Realistically, however, the variables would be measured with some error. Therefore, I transformed the true score variables into “observed”, error-laden variables by adding some random noise into them so that the reliability of each is 0.80. When I regressed log weekly wages on the four observed explanatory variables and the gender dummy variable, the results looked like this:
| DV: Log weekly wage | ||||
| B | 95% CI | p | ||
| (Intercept) | 6.91 | 6.90 – 6.92 | <.001 | |
| Observed hours worked | 0.20 | 0.19 – 0.20 | <.001 | |
| Observed work experience | 0.20 | 0.19 – 0.21 | <.001 | |
| Observed field of employment | 0.20 | 0.19 – 0.21 | <.001 | |
| Observed occupational level | 0.20 | 0.19 – 0.20 | <.001 | |
| Gender | -0.05 | -0.07 – -0.04 | <.001 | |
| Observations | 20000 | |||
| R2 / adj. R2 | .422 / .422 | |||
It can be seen, first, that the coefficients for each of the four explanatory variables are lower than in the previous model and the R^2 is also lower. This is a consequence of the added measurement error: less reliable variables explain less variance. More strikingly, the gender dummy, which was non-significant in the previous model, is now highly significant. In this model, there is a gender pay gap of e^-0.05-1 ≈ -5%, favoring men, even after controlling for the four explanatory variables.
The model reported in Table 8 and the variables used in it are exactly the same as in the model in Table 7 save for the random measurement error added to the independent variables. Therefore, we can conclude that the conditional gender pay gap of -5% suggested by the model is entirely spurious and artifactual, an example of Kelley’s paradox. The paradox affects the intercept of the regression equation, making it smaller for the group with lower mean values for the independent variables. In contrast, the slope coefficients are not (differentially) affected; they are equal for the two groups. This can be ascertained by running the model with interaction terms which allow the slopes to differ between sexes:
| DV: Log weekly wage | ||||
| B | 95% CI | p | ||
| (Intercept) | 6.91 | 6.90 – 6.92 | <.001 | |
| Observed hours worked | 0.20 | 0.19 – 0.20 | <.001 | |
| Observed work experience | 0.20 | 0.19 – 0.21 | <.001 | |
| Observed field of employment | 0.20 | 0.19 – 0.21 | <.001 | |
| Observed occupational level | 0.20 | 0.19 – 0.20 | <.001 | |
| Gender | -0.05 | -0.07 – -0.04 | <.001 | |
| Gender × obs hours | 0.00 | -0.01 – 0.01 | .906 | |
| Gender × obs experience | 0.00 | -0.01 – 0.01 | .912 | |
| Gender × obs field | 0.00 | -0.01 – 0.01 | .956 | |
| Gender × obs occupational level | -0.00 | -0.02 – 0.01 | .688 | |
| Observations | 20000 | |||
| R2 / adj. R2 | .422 / .422 | |||
None of the interaction terms (denoted by ×) are different from zero, confirming that measurement error only makes the intercepts, not the slopes, different between groups. This makes it easy to misinterpret the results as showing that while the independent variables predict higher wages for both groups in a similar, linear fashion, there is simultaneously a constant bias whereby women are paid less at all levels of the independent variables.
The artifact is caused by the fact that the true score value underlying any given observed value is smaller, on average, for women than for men. If the four explanatory variables were remeasured, both men and women would exhibit RTM, but women would regress to their own, lower means. This can be verified by separately regressing true scores on observed scores in men and women. The graph below shows the regressions for work experience (in z-score units), but the results are the same for all four variables.
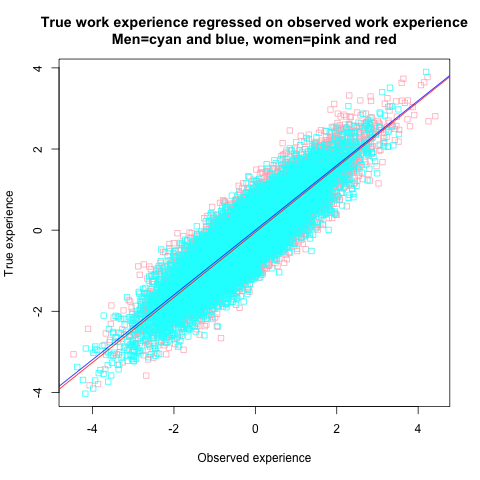
Figure 15.
While it may be difficult to discern from the graph, the intercept of the red female regression line is slightly lower than that of the blue male line. Specifically, the expected true work experience (T) predicted from observed work experience (X) is for men simply:
E(Tmen) = 0.80 * X
For women it’s:
E(Twomen) = -0.05 + 0.80 * X
Observed experience slightly overestimates the true experience that women have compared to men. This small intercept bias that is due to random measurement error causes, together with similar biases in the three other explanatory variables, the spurious gender pay gap of -5% seen in the regression model.
While the variables in my analysis are simulated, Kelley’s paradox is a plausible explanation for the residual gender pay gap found in many studies that have attempted to explain the gap by controlling for productivity-related variables. As few variables are measured without error, I don’t see how it could be otherwise. Nevertheless, this is rarely recognized in econometric literature where the pay gap is often studied, even though the effect of measurement error on parameter estimates is hardly something that econometricians are unaware of (even if they don’t use terminology like “Kelley’s paradox”). For example, in Blau & Kahn’s (2016) otherwise exhaustive analysis of the gender pay gap, it is acknowledged that the residual pay gap that remains after controlling for various covariates may be caused by unmeasured variables (rather than discrimination), but what is not discussed is the fact that a gap would remain even if all the relevant variables were included in the regression model and discrimination were non-existent. Measurement error introduces a bias in the estimates that is similar to the bias caused by omitted independent variables.[Note]
As usual, true score estimates based on sex-specific mean values can be used to adjust for the intercept bias introduced by measurement error.[Note] Table 10 shows that the use of true score estimates brings the unstandardized slope estimates very close to their true values (compare to Table 6), eliminating the spurious gender effect. (The R^2 of the model is not improved compared to models using observed scores because the within-gender correlation between true score estimates and observed scores is 1.)
| DV: Log weekly wage | ||||
| B | 95% CI | p | ||
| (Intercept) | 6.91 | 6.90 – 6.92 | <.001 | |
| Estimated true hours | 0.25 | 0.24 – 0.26 | <.001 | |
| Estimated true experience | 0.25 | 0.24 – 0.26 | <.001 | |
| Estimated true field of employment | 0.25 | 0.24 – 0.26 | <.001 | |
| Estimated true occupational level | 0.24 | 0.24 – 0.25 | <.001 | |
| Gender | -0.00 | -0.02 – 0.01 | .826 | |
| Observations | 20000 | |||
| R2 / adj. R2 | .422 / .422 | |||
9. Sampling from the tails
As I noted at the start of this post, RTM is not always caused by random measurement error. Sometimes individuals with extreme variable values regress towards the mean over time for reasons inherent to them and their circumstances that have nothing to do with measurement error.
Above, I used the example of people spontaneously recovering from depression. Another classic example of how “sampling from the tails” makes statistical analysis tricky is Horace Secrist’s (1881–1943) book The Triumph of Mediocrity in Business (1933). Secrist was a noted economist and statistician, but it did not prevent him from making the cardinal mistake of ignoring RTM. In the book, he analyzed the profitability of companies over years, showing that firms that are highly profitable or non-profitable in a particular year tend to become more mediocre in subsequent years. From these data, he concluded that economic life was characterized by increasing mediocrity.
Secrist’s results are of course just another example of regression (and egression): if we examine a group of companies with particularly high or low earnings this year, they will tend to become more mediocre in the following years, as this year’s particularly lucky or unlucky circumstances fade away (meanwhile, other companies “inherit” that good or bad luck). The unstable element that makes a company’s profits extreme is analogous to measurement error, but it is not caused by limitations in measurement instruments and is not noise in that sense (it’s hard, cold cash or lack thereof).
10. RTM due to reliable but non-transmissible influences
Thus far, we’ve dealt in more or less detail with RTM cases where the non-reliable component of a variable either consists of random error or is due to within-subject changes in true scores over time. However, RTM can exert a strong influence even when a variable’s value is stable within individuals and not much affected by measurement error. A classic example of such a process is familial resemblance in phenotypic traits.
Between-individual differences in a given human trait can, at least in principle, be decomposed into variance components in roughly the following manner, assuming that, like most (adult) human traits, this trait is not significantly influenced by shared (familial) environmental effects, and that the different influences are normally distributed and independent of each other:
VX = VA + VD + VE1 + VE2
where
V = variance
X = individuals’ trait values
A = individuals’ additive genetic values (summed across the genome)
D = individuals’ dominance values (values due to genetic interactions at the same loci summed across the genome)
E1 = values representing non-genetic influences unshared between relatives (e.g., accidents, “developmental noise”)
E2 = random measurement error scores
(E1 and E2 are usually rolled into one single non-shared environmental component, but for illustrative purposes they’re separated here.)
Let’s say that some trait fits this model (in each generation), and its additive genetic variance (VA) is 0.60, while dominance variance (VD) is 0.20, and the variances of E1 and E2 are 0.10 each. The variances sum up to 1, which is the variance of the phenotypic values (VX). Because of the scale chosen, the variances can be treated as standardized, e.g., VA=0.60 means that narrow-sense heritability is 60%. The means for X, A, D, E1, and E2 are all 0. A further assumption is that mating is random with respect to this trait.
Now let’s say that there’s a couple with extreme trait values (X). The couple’s average trait value, called the midparent value, is 2 SDs above the population mean (that is, Xmidparent = 2). What would you expect the trait values of their children be?
To answer that question, we need, first, to know what caused the parents to have such extreme trait values. We cannot know the answer for certain. This is because X = 2 can result from different combinations of influences. Sometimes people have high trait values because their genetic values are high, other times it’s because they have high non-genetic or measurement error values. Therefore, we have to settle for the answerable question of why parents who score X = 2 do so on average.
We know the causal model for how A, D, E1, and E2 give rise to different values of X:
X = A + D + E1 + E2
When the variances of dependent and independent variables are equal, as in the case of parallel tests discussed before, the regression slope is the same regardless of which variable is dependent and which is independent. The slope equals the correlation, and the expected deviation from the mean of either variable conditional on the deviation value of the other equals the product of the correlation and that conditional value, as expressed in Kelley’s true score formula. If the variances aren’t equal, as is the case here, the formula is slightly more elaborate (Campbell & Kenny, 1999, p. 26). For example, the expected value of A conditional on given values of X is given by:
E(A) = MA + corrA, X * (SDA / SDX) * (X - MX)
where M refers to the variables’ mean values. Given that the means of A and X are 0, the equation simplifies to:
E(A) = corrA, X * SDA / SDX * X
The correlation between A and X is √0.6 because A explains 60% of X’s variance. The SD of A is also √0.6. Therefore, the expected value of A conditional on X is:
E(A) = √0.6 * √0.6 / 1 * X = 0.6 * X
The expected values of D, E1, and E2 can be calculated in the same way. Because A, D, E1, and E2 are independent of each other, their expected values do not depend on each other. The expected values of D, E1, and E2 are:
E(D) = 0.2 * X E(E1) = 0.1 * X E(E2) = 0.1 * X
The expected values for A, D, E1, and E2 for a given level of X are therefore obtained simply by multiplying the variances of each with X. If X = 2, then:
E(A) = 0.6 * 2 = 1.2 E(D) = 0.2 * 2 = 0.4 E(E1) = 0.1 * 2 = 0.2 E(E2) = 0.1 * 2 = 0.2
These are the average midparent values when Xmidparent = 2.
The next question is how these values of A, D, E1, and E2 are transmitted over generations. Let’s look at the environmental components first.
E1 is an environmental or, more broadly, non-genetic component that affects only a specific individual; related individuals are not more similar on E1 than unrelated individuals. It is the set of unique trait-relevant experiences and influences that the individual has faced in his or her life. Therefore, parents’ E1 values cannot influence their offspring’s trait values, and children have an expected value of 0 for E1, 0 being the mean of E1’s population distribution.
Secondly, E2 is a random measurement error component. It is something that does not carry over even between different measurement occasions for the same individual, so parents’ E2 values also cannot influence their children. The expected value of the offspring for E2 is therefore 0.
With only the A and D components remaining, it’s clear that parent-offspring resemblance is determined solely by genetic influences. From quantitative genetic theory we know that different components of genetic variance cause similarities between parents and offspring in the following manner (from Falconer & Mackay, 1996, p. 155; note that the “parent” in the offspring-parent covariance can be either one parent or the midparent):
Table 11.

The model specified earlier includes additive variance, VA, and dominance variance, VD. The other variance components mentioned in the table do not contribute to the variance of the trait.[Note] As the table indicates, VA contributes to parent-offspring resemblance while VD does not. The covariance of offspring and parents for X is therefore simply 0.5 * VA = 0.5 * 0.6 = 0.3.
Now, to calculate the expected offspring trait values for given midparent trait values, we regress offspring values on midparent values:
E(Xoffspring) = B * Xmidparent
The slope coefficient B is equal to the covariance of Xoffspring and Xmidparent divided by the variance of Xmidparent. The variance of midparent X values is half the variance of individual X values. Therefore, B = 0.3 / 0.5 = 0.6. The expected phenotypic trait value of the offspring is 0.6 * Xmidparent.
B equals the additive heritability of the trait, which is not a coincidence: when there are no shared environmental influences (or epistasis), the regression of offspring trait values on midparent trait values equals heritability.
The breeder’s equation condenses the foregoing considerations into a simple formula:
R = h^2 * S
where
R = response to selection
h^2 = additive heritability
S = selection differential
Now consider again our couple whose midparent phenotypic value X is +2 SDs above the population mean while narrow-sense heritability is 0.6. Applying the formula, we get R = 0.6 * 2 = 1.2. This means that, on average, parents who score 2 SDs above the mean will have children who score only 1.2 SDs above the mean. RTM happens in this situation because only the additive genetic effects on parents’ traits are passed on to children. (The additive genetic values of children are, on average, equal to those of their midparent. The additive genetic value is for this reason also called the breeding value.) For parents with Xmidparent = 2, the average midparent values for D, E1, and E2 are 0.4, 0.2, and 0.2, respectively. Given that the additive genetic component is uncorrelated with the other components (D, E1, and E2) in the population, the offspring’s expected values for those other components are equal to population mean values, 0, causing them to regress compared to their parents. In short, when Xmidparent = A + D + E1 + E2 = 1.2 + 0.4 + 0.2 + 0.2 = 2, then E(Xoffspring) = 1.2 + 0 + 0 + 0 = 1.2.
If the offspring generation of the example were to have children with each other randomly and endogamously, their children would not regress towards the grand population mean of 0. Instead, the mean X of the grandchild generation would be 1.2, the same as that of their parents. This is because the non-transmissible influences on X, namely D, E1, and E2, are 0, on average, in the first offspring generation, precluding RTM from happening in subsequent generations. If this group of people continues to mate randomly and endogamously over generations, their mean X will remain at 1.2 perpetually (provided that the causal model underlying X does not change with time).
To recap, according to my model—which, while a simplification, fits lots of real-life traits reasonably closely—parents cannot transmit other influences on traits than additive genetic ones to their children. This causes the children of parents with extreme phenotypic values to regress towards the population mean by an amount that can be predicted using the breeder’s equation. This is so despite the fact that those other influences, except for measurement error, are more or less stable and not subject to RTM effects in the parents themselves.
11. RTM and the etiology of IQ differences between groups
Arthur Jensen noted a long time ago that when you match black and white individuals on IQ (or, preferably, on true score estimates of IQ), and then compare the IQs of these individuals to the IQs of their siblings, you will notice that the siblings of the black individuals will score lower than the siblings of the white individuals. Statistically, black and white siblings regress towards different means, and these regressions appear to be quite linear across the range of ability. For example, Murray (1999) reported regressions where blacks and whites from various NLSY surveys were grouped into a handful of IQ ranges (e.g., those scoring around 70, around 80, around 90, etc.) based on AFQT and PPVT scores and these group IQs were used to predict the IQs of the group members’ siblings. The following graphs show Murray’s results, with each dot representing something like a dozen to a hundred pairs of siblings:
Figure 16.
Figure 17.
Jensen argued that the different regressions provide evidence for his hereditarian explanation of the black-white IQ gap. His critics, however, have countered that the regressions towards different means could be due to environmental mechanisms.
From Table 11 in the previous section we find out that the genetic covariance of siblings equals 0.5 * additive genetic variance plus fractional (and usually substantively small to non-existent) contributions from genetic interaction components. This means that the correlation between siblings (monozygotic twins excepted) is much less than 1 and usually less than 0.5, unless the shared environment has a strong influence (which it hasn’t after childhood). This less than perfect correlation leads to RTM whereby the siblings of individuals with IQs far from the population mean score much closer to the mean. Given that the mean IQ of blacks is about 15 points lower than that of whites, we see the phenomenon illustrated in Figures 16 and 17.
Let’s say that the sibling correlation for IQ is 0.4. The following equation, where M is the population mean, gives the expected comparison sibling IQ based on the reference sibling’s IQ:
E(IQcomparison sib) = M + 0.4 * (IQreference sib - M)
It’s clear that if the reference individuals—those whose IQs are matched—come from populations with different mean IQs, their siblings will not have the same expected IQs. RTM “pulls” the IQs of the comparison siblings towards the respective means of the two populations.
Results like Murray’s above are a reflection of the fact that there’s a similar linear relation between sibling IQ scores in blacks and whites. The differential regression effect results from the fact that that only the familial component is shared between siblings whereas the non-familial, “non-transmissible” components aren’t. The farther from the mean an IQ score is, the more likely it is that it is strongly influenced by those non-transmissible influences. For this reason, the comparison siblings statistically regress towards the relevant population means.
The familial component of IQ variance appears to be overwhelmingly and roughly equally genetic in blacks and whites. This suggests that the regression effect is due to black-white differences in the genes underlying IQ.
Of course, it’s possible to argue that the mean value of the familial component is actually the same in blacks and whites and that differential regression happens because blacks are disadvantaged on the non-familial component, or that there’s a constant non-genetic “X-factor” that causes the gap. As I’ve argued elsewhere, such environmental explanations, if properly formalized, will face great difficulties in explaining the facts at hand. Nevertheless, the regression effect as such is only consistent with the genetic explanation; other models might explain the gap as well. Structural equation models that incorporate group means could take the discussion about the regression effect and its causal implications further, as was done in Rowe and Cleveland’s (1996) small pilot study. Unfortunately, after David Rowe’s untimely death no one has pursued this line of research.[Note]
12. Discussion
Selecting individuals who have extreme variable values usually means selecting observations that are biased by larger than usual amounts of measurement error or other transient, unstable influences. If you remeasure the variable, such selected individuals are likely to regress towards the mean because the transient influences that caused many of them to have extreme values earlier are now absent. This is the mechanism underlying the phenomenon of regression to the mean.
RTM by itself does not cause permanent change in the distribution of a variable’s values. When some individuals regress towards the mean upon remeasurement, others egress away from the mean, taking the places that those “regressed” individuals previously occupied in the distribution. Regression and egression are terms given to transitory influences that affect different people over time.
Measurement error makes group comparisons challenging in situations where groups’ mean values for the variable(s) of interest differ. Kelley’s paradox refers to the fact that measurement error causes the observed values of groups with low mean values to overestimate true values when compared to the observed values of groups with high mean values. This results in the overprediction of the low-scoring groups’ performance. I used the black-white IQ gap and the gender pay gap to demonstrate Kelley’s paradox, but the phenomenon is entirely general and can affect any kinds of groups and variables.[Note]
Group mean values contain information that is not included in unreliable observed variable values. This means that even when you have access to individuating information, it does not make sense, from a strictly statistical perspective, to treat individuals from different groups in the same way if the groups have substantially different mean values for the variables of interest. If you match individuals on observed variable values, individuals from groups with higher mean values are likely to have higher true score values than individuals from groups with lower mean values. Using true score estimates instead of observed scores is one way of adjusting for this bias. True score estimates work because they are based on the statistical certainty that unreliable observed scores regress towards their true values and the mean if remeasured.
RTM often happens because observations are sampled from the tails of the distribution. Upon remeasurement, individuals (or other units of analysis) with extreme values may regress towards the mean not only because of measurement error, but also because it is in the nature of the variable’s true score values to be unstable within individuals. When repeated measurements of such variables are taken, it is fallacious to attribute changes in variable values to external causes if natural variability is not accounted for.
The regression of offspring towards the population mean from the phenotypic values of their parents is an observation that helped Francis Galton discover the general statistical phenomenon of RTM. Familial regression is caused by the fact that expected familial resemblance in most phenotypic traits is almost completely determined by additive genetic influences (except in monozygotic twins who share just about all genetic effects, including non-additive ones). Other influences than additive genetic ones always contribute to trait variation, and (adult) family members are usually no more similar with respect to those other influences than random strangers in the same population. To the extent that individuals’ extreme trait values are not determined by their extreme additive genetic values, their relatives will, on average, have trait values that are less extreme and closer to the population mean. The breeder’s equation is a simple formula that can be used to predict the magnitude of the familial regression effect.
Notes
1. While observed scores are formed by summing true and error scores, the sum of the SDs of the latter two—13.42+6.71=20.13 here—does not equal the observed SD of 15. This is because SDs, unlike variances, are not additive. To get the SD of the observed scores, you take the square root of the sum of the true and error variances: √(13.42^2+6.71^2)=15.
2. Emil Kirkegaard, who read a draft of this post, pointed out that continuous distributions don’t have “most common values”. I admit that the language I’ve used in this post may be mathematically loose in places, but I’m trying to make my arguments widely accessible, so more intuitive explanations take precedence even if they aren’t always technically quite accurate. In any case, I generally use values of true and observed scores that are rounded to closest integers, so those distributions are in effect discrete.
3. Given that the variances of the first and second tests are the same (namely, 15^2=225), the slope is equal to the correlation between the two. The reliability of the test is also 0.80, which is not a coincidence. The traditional psychometric definition of reliability is that it is the correlation between two parallel tests, parallel tests being tests that measure the same true scores with the same reliability.
The fact that the reliability of parallel tests is equal to the correlation between them is easy to grasp when you draw a path diagram of the relationships between (standardized) true scores and tests:
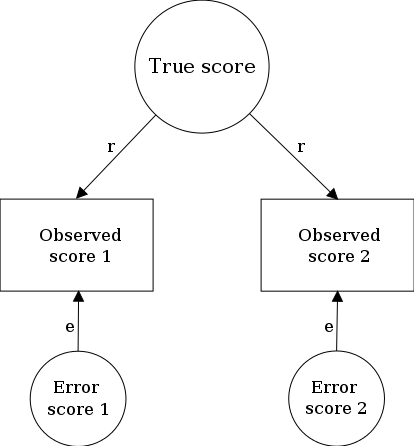
In this diagram, the correlation of true scores with observed scores in either test is r. The reliability of the tests is the proportion of variance that true scores explain in them, or r^2. Tracing rules for path diagrams tell us that the correlation between the parallel tests is r*r = r^2, which equals the reliability.
4. The SD is 13.42 rather than 15 because it’s the true score distribution which is narrower than the observed score distribution. SD=13.42 corresponds to a reliability of 0.80 because √(0.8*(15^2))~13.42.
5. Error scores and true scores are uncorrelated by definition in true score theory and therefore also in my simulations. In practice, it is possible that the reliability of a test or other variable varies as a function of true score level. For example, an IQ test may not contain sufficient numbers of items for each ability level. Such problems, which can be addressed with item response theory models, are ignored in this post.
6. Kelley’s true score formula, like all shrinkage estimators, trades off unbiasedness for lower mean estimation error. Psychometrics has always developed somewhat independently of “mainstream” statistical science, so it’s interesting that Kelley’s formula actually predates the development of shrinkage estimation by Charles Stein and others by several decades. This is another example of what Andrew Gelman has called a “longstanding principle in statistics”: Whatever you do, somebody in psychometrics already did it long before.
7. If you have results from two or more parallel tests, you can construct more reliable observed scores by summing the scores across tests. In my simulated data, the correlation between true scores and the sums of the two observed scores is 0.943. Squaring it, we get ~0.89, which is the reliability of the sum scores.
The reliability of such sum scores can also be estimated analytically. The Spearman-Brown prediction formula gives an estimate of how much reliability increases when you multiply the length of a test. In the case of two parallel tests with a reliability of 0.80, the Spearman-Brown estimate for the reliability of their sum scores is 2*0.8/(1+(2-1)*0.8) ≈ 0.89, matching the simulated example.
8. I’m not sure who first recognized the existence of Kelley’s paradox. It is implicit in Kelley’s own writings in the 1920s, but I haven’t found an explicit discussion of it in them. It was in any case acknowledged early on in psychometrics, because a 1942 article about the paradox in Psychometrika starts with a disclaimer that the article is “in the nature of a reminder of old truths, rather than a message of startling novelty” (Thorndike, 1942). More modern treatments include Jensen (1980, pp. 94–95, 275–277, 383–386), Linn (1984), and Millsap (1998, 2007).
9. It may help to understand why the intercept bias happens when true scores are regressed on observed scores but not the other way round if you remember that in regression analysis random measurement error in the independent variable(s) biases the estimates downwards while error in the dependent variable does not bias the estimates (it only increases their standard errors). If you standardize your variables, as in correlation analysis, measurement error will bias the estimates regardless of which variable is affected by it.
10. A simplification in this post is that I treat the true scores underlying a test as unitary. In practice, the reliable portion of a test’s variance is almost always multidimensional. For example, while IQ scores mostly reflect g variance, they are always “flavored” by the specific tests used, the more so the less diverse the test battery is.
Gignac (2015) factor-analyzed Raven’s Progressive Matrices together with many other tests taken by the same individuals. He found that when he decomposed Raven’s scores into orthogonal sources of variance that they shared with scores from other tests, the variance of the Raven’s scores was approximately 50% due to g and 10% due to fluid intelligence, while an additional 25% was due to variance specific to the Raven’s test. This comes up to 85%, meaning that 15% of Raven’s matrices variance was due to measurement error in this sample. The true score variance of the Raven’s was 85%, which, however, cannot be treated as coterminous with any single latent construct because of its underlying multidimensionality.
In the case of one population, it seems to me that little is loss in terms of generality when true scores are treated as unitary when discussing RTM—what is reliable is reliable regardless of what it precisely is. However, when there are group differences and only some portion of the reliable variance—for example, only the g variance of Raven’s scores—is correlated with both criterion outcomes and group differences, Kelley’s paradox may have a larger effect than what one would predict based on test-retest reliability. For simplicity’s sake, I have ignored the multidimensionality of true scores in this post.
11. For real data, true scores are never available, unlike in my simulation. When measurement invariance is examined in real data sets, true scores are assumed to be equal to the shared variance of the observed variables that are used as indicators of the true underlying variable. For example, the shared variance of a number of different cognitive ability tests may be assumed to be equal to a latent true score variable labeled as general intelligence, or g. The larger the number of indicator variables that are used, the less there is psychometric sampling error and the more accurately the underlying true score variable is captured.
12. The intercept difference was statistically significant in 26 of the 72 GATB studies. In 25 of them the black intercept was smaller, while the white intercept was smaller in one study. Many of the individual studies were rather small, with as few as 50 workers from each race, so it is not surprising that there aren’t always significant differences.
13. It’s possible that overprediction is not solely due to Kelley’s paradox. It could also be due to biased criterion variables or due to influences other than IQ that correlate with both the criterion variables and race. However, the presence of mean group differences and unreliability in the independent variable is always expected to result in at least some differential prediction.
14. True score estimates inflate any group differences that exist. This happens not because Kelley’s formula changes group means (it doesn’t) but because it decreases within-group variances by assuming that everybody—rather than just the average person—who scored X in the first test would regress to the same score in a retest. In the simulation, the observed IQ difference between blacks and whites is 15 points, or 1 SD, while the true score difference is larger, namely 15/13.42 ≈ 1.12 SDs. The gap in true score estimates is even larger because the SD is only 12—15/12 = 1.25 SDs. The upside to this bias is, however, that when used in selection settings, true score estimates eliminate group differences in sensitivity, or the true positive rate, as shown in Figure 11 above.
An additional problem in selection is that the specificity (aka the true negative rate) of observed scores is lower in the group with a higher mean score. Borsboom et al. (2008) illustrate how Kelley’s paradox leads to differences in sensitivity and specificity between high-scoring (H) and low-scoring (L) groups in the following way:

Point Xc on the y-axis represents the selection decision cut-off point based on observed scores, while point θc on the x-axis shows the true score cut-off point. Compare the ratios of H and L groups, whose distributions are represented by the two ellipses, in different quadrants. For example, the majority of accepted H group members are true positives while the majority of accepted L group members are false positives. The exact magnitude of these biases depends on factors such as the size of the group difference and how stringent selection is, but some bias is always expected when the test used is unreliable and there are group differences in test scores. True score estimates eliminate group differences in both specificity and sensitivity.
15. The intercept equals the mean log weekly wage for males, 6.91, because the intercept is what you get when you set all independent variables to zero. The male means for the four explanatory variables are zero, and the gender dummy value is also zero for males.
The unstandardized regression coefficients (B) can be interpreted by transforming them from log scale to the original dollar scale. One SD increase in any of the four explanatory variables corresponds to e^0.25-1 ≈ 28 percent increase in weekly wages in dollars. The transformed intercept is e^6.91 ≈ 1000 which is the mean weekly wage in dollars for men.
16. There is in fact a substantial albeit somewhat confusing (or confused) econometric literature on how measurement error biases gender pay gap regressions, with Goldberger (1984) as a typical example, although the original stimulus for this literature seems to have been a paper by a psychologist: Birnbaum (1979). Nevertheless, contemporary treatments of the gender pay gap tend to omit any discussion of measurement error.
17. True score estimation is not the only way to deal with measurement error. Other options include errors-in-variables regression and structural equation modeling with error components. Still another solution is, of course, to get more data until your measurements are so reliable that issues such as Kelley’s paradox do not matter. This, however, is usually not feasible.
18. The simplification I adopted in my model whereby dominance effects are the only non-additive genetic effects affecting the trait is generally not too unrealistic. Both theory and empirical evidence indicate that while interactions between loci (epistasis) are common in individuals, they do not generally make genetic differences between individuals non-additive because “multilocus epistasis makes substantial contributions to the additive variance and does not, per se, lead to large increases in the nonadditive part of the genotypic variance” (Maki-Tanila & Hill, 2014; see also Hill et al., 2008). Not only is the effect of epistasis small at the population level, only a fraction of that effect contributes to familial covariance, as indicated in Table 11 above, making it in practice difficult to estimate its effect, if any.
19. Rowe and Cleveland’s approach reflects what Arthur Jensen called the default hypothesis: group differences arise from the same factors as individual, within-group differences, even if not necessarily to the same degrees. In contrast, Eric Turkheimer has argued that group differences are not amenable to behavior genetic analysis. Turkheimer’s claim seems to me to rely on an a priori, metaphysical insistence on the uniqueness of group processes. It also seems a rather strange claim in the face of the fact that he is most famous for his research on social class differences in the determinants of IQ—which, if the exhortations in the linked piece are to be taken seriously, would appear to say nothing about the causes of social class differences in mean IQ. More broadly, the entire science of medical genetics is based on the theory that individuals affected and unaffected by a given disease differ genetically from each other. Would Turkheimer argue that medical genetics has not established, and will never establish, the genetic basis of diseases?
Personally, I subscribe to the sort of causal uniformitarianism that Jensen (1973) described in this way:
“There is fundamentally, in my opinion, no difference, psychologically and genetically, between individual differences and group differences. Individual differences often simply get tabulated so as to show up as group differences—between schools in different neighborhoods, between different racial groups, between cities and regions. They then become a political and ideological, not just a psychological, matter.”
20. One area where failures to appreciate Kelley’s paradox have frequently led to unjustified accusations of biased decision-making is the criminal justice system. Given that there are large racial differences in propensities for criminal offending, applying identical decision rules to offenders from different races will necessarily lead to statistical disparities in the treatment of different races. I’ll probably write another post devoted to this specific topic.
References
Birnbaum, M. H. (1979). “Procedures for the Detection and Correction of Salary Inequities.” In Salary Equity, eds. T. R. Pezzullo and B. E. Brittingham. Lexington, MA: Lexington Books, 1979. Pp. 121-44.
Blau, F. D. & Kahn, L. M. (2016). The Gender Wage Gap: Extent, Trends, and Explanations. NBER Working Paper No. 21913.
Braun, H., & Jones, D. (1981). The Graduate Management Admission Test prediction bias study. (Graduate Management Admission Council, Report No. 81-04, and Educational Testing Service, RR-81-25). Princeton, NJ: Educational Testing Service.
Campbell, D. T. & Kenny, D. A. (1999). A Primer on Regression Artifacts. New York: The Guilford Press.
Falconer, D. S., Mackay, T. F. C. (1996). Introduction to quantitative genetics (4th ed.). Essex, UK: Longman.
Frey, M. C., & Detterman, D. K. (2004). Scholastic assessment or g? The relationship between the scholastic assessment test and general cognitive ability. Psychological Science, 15(6), 373-378.
Galton, F. (1885). Regression Towards Mediocrity in Hereditary Stature. Journal of the Anthropological Institute, 15, 246-263.
Gignac, G. E. (2015). Raven’s is not a pure measure of general intelligence: Implications for g factor theory and the brief measurement of g. Intelligence, 52, 71–79.
Goldberger, A. S. (1984). Reverse Regression and Salary Discrimination. Journal of Human Resources, 19(3), 293-318.
Hartigan, J. A., & Wigdor, A. K. (Eds.). (1989). Fairness in employee testing: Validity generalization, minority issues, and the General Aptitude Test Battery. Washington, DC: National Academy Press.
Hill, W. G., Goddard, M.E., Visscher P.M. (2008). Data and Theory Point to Mainly Additive Genetic Variance for Complex Traits. PLoS Genet 4(2): e1000008.
Jensen, A. R. (1973). On “Jensenism”: A reply to critics. In B. Johnson (Ed.), Education yearbook, 1973-74. New York: Macmillan Educational Corporation. Pp. 276-298.
Jensen, A. R. (1980). Bias in mental testing. New York: Free Press.
Kelley, T. L. (1923). Statistical Method. New York: The Macmillan Company.
Kelley, T. L. (1927). Interpretation of Educational Measurements. New York: World Book Company.
Koenig, K. A., Frey, M. C., & Detterman, D. K. (2008). ACT and general cognitive ability. Intelligence, 36, 153–160.
Linn, R. L. (1984). Selection bias: Multiple meanings. Journal of Educational Measurement, 21, 33-47.
Maki-Tanila, A., & Hill, W. G. (2014). Influence of Gene Interaction on Complex Trait Variation with Multilocus Models. Genetics, 198(1), 355–367.
Mattern, K., Patterson, B., Shaw, E., Kobrin, J., & Barbuti, S. (2008). Differential validity and prediction of the SAT. New York: College Board.
Miller, E. M. (1994). The relevance of group membership for personnel selection: A demonstration using Bayes’ theorem. Journal of Social, Political, and Economic Studies, 19, 323–359.
Millsap, R. E. (1998). Group differences in regression intercepts: Implications for factorial invariance. Multivariate Behavioral Research, 33, 403–424.
Millsap, R. E. (2007). Invariance in measurement and prediction revisited. Psychometrika, 72, 461– 473.
Murray, C. (1999). The Secular Increase in IQ and Longitudinal Changes in the Magnitude of the Black-White Difference: Evidence from the NLSY. Paper presented to the Behavior Genetics Association Meeting, 1999.
Rowe, D. C., & Cleveland, H. H. (1996). Academic achievement in Blacks and Whites: Are the developmental processes similar? Intelligence, 23, 205–228.
Thorndike, R. L. (1942). Regression fallacies in the matched groups experiment. Psychometrika, 7, 85-102.
Verhaeghen, P. & Salthouse, T. A. (1997). Meta-analyses of age-cognition relations in adulthood: estimates of linear and nonlinear age effects and structural models. Psychological Bulletin, 122, 231–50.
Wainer, H. (2000). Kelley’s Paradox. Chance, 13, 47-48.
Wainer, H., & Brown, L. M. (2007). Three statistical paradoxes in the interpretation of group differences: Illustrated with medical school admission and licensing data. In C.R. Rao and S. Sinharay (Eds.), Handbook of statistics Vol. 26: Psychometrics (pp. 893–918). Amsterdam, The Netherlands: North-Holland.
Wightman, L. F., & Muller, D. G. (1990). An Analysis of Differential Validity and Differential Prediction for Black, Mexican American, Hispanic, and White Law School Students. Law School Admission Council Research Report 90-03. Newtown, PA: Law School Admission Services.
Appendix: R code
Here’s the code for reproducing the simulations, graphs, and analyses from this post.
Discover more from Human Varieties
Subscribe to get the latest posts sent to your email.

” For example, if you take a difficult multiple-choice IQ test and make several correct guesses when you don’t know the answers, leading to you getting a very high test score, your score when retaking the test will likely regress towards the mean as you will probably not be as lucky with your guesses the second time around.” – I see where you’re at with this statement, but in a statistical sense, “luck” seems to me to be fictional. I would prefer the statement that my old stats Prof made – that reliability of measurement is lower in the range of extreme scores than it is when they occur close to the mean.
Unreliability is caused by “trait-irrelevant” influences such as guessing. Extreme scores are often extreme precisely because they have been disproportionately affected by guessing and the like. I don’t see how it’s fictional.
Maybe. What then is your opinion of “the gambler’s fallacy?” Is it a fallacy?
It’s a fallacy if the events are actually causally independent.
Very good article. Thanks.
1. The recent book by Gary Smith, “What the Luck”, extensively uses Kelley’s equation.
2. The url you have given above for downloading books by Kelley
https://cda.psych.uiuc.edu/kelley_books/
no longer works. 🙁 Hope there’ll be a working source for them.