Race/ethnic cognitive/academic achievement gaps are considered so important in the social sciences that number 4 in the social science’s top 10 list of “grand challenge questions that are both foundational and transformative” (Giles, 2010) is: “How do we reduce the ‘skill gap’ between black and white people in America?” Illustrating just how much effort has been focused on this topic, Google scholar yields 48,200 search results when queried for “race” and “achievement gaps.” The concern is arguably well justified as race/ethnic-related social outcome gaps can largely be accounted for by differences in cognitive ability (e.g., Fryer, 2014).
Given the intensity of academic interest in this subject, the fact that only a handful of researchers are focused on understanding why achievement gaps so tightly track genetically-identified ancestry within socially-identified racial/ethnic groups is indeed curious. For instance, in Guo, Lin, & Harris (2019), the authors report results for Peabody Picture Vocabulary based on the ADD Health sample. In Table 3 of said publication, among Hispanic and non-Hispanic Blacks, ancestry principle components PC1 and PC3 are strongly associated with verbal intelligence. And among non-Black Hispanics, ancestry principle components PC2 and PC3 show the strongest association.
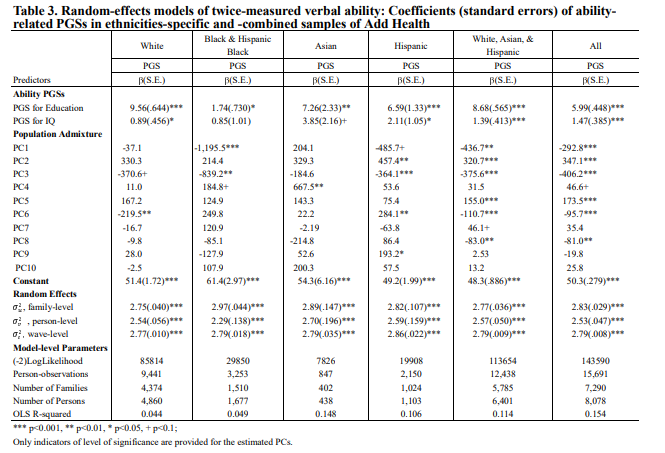
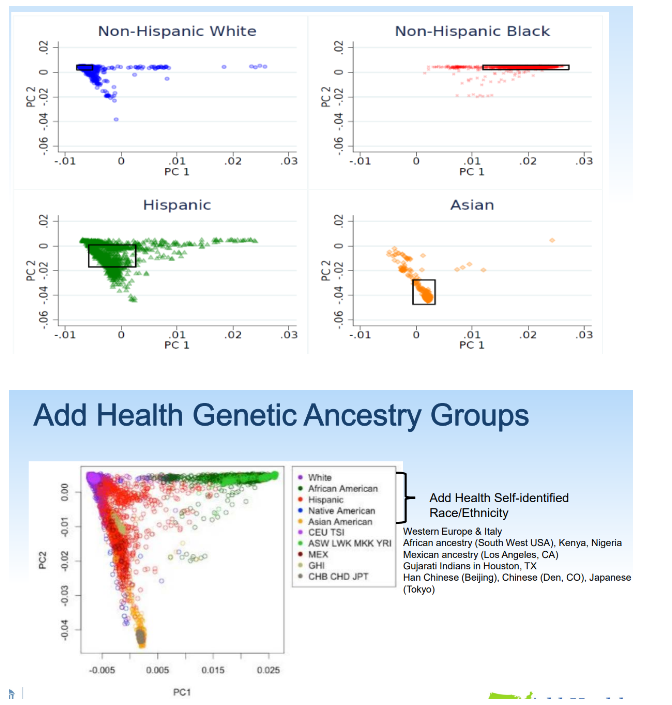
In their report, Braudt & Harris (2020) provide the Rosetta Stone for interpreting these otherwise opaque results. PC1, in this sample, separates Sub-Saharan African ancestry from out-of-African ancestry, while PC2 separates European ancestry from non-European out-of-African ancestry. PC3 is not shown, but we can deduce from the distribution among Black and non-Black Hispanics that it separates out Amerindian ancestry. In other words, in this large national sample – just as in the nationally representative Adolescent Brain Cognitive Development study (Fuerst, 2021) – African and Amerindian genetic ancestry are strongly negatively related to intelligence among socially-defined Blacks and Hispanics.
Once again, despite these robust findings, armies of sociologists nominally interested in the source of racial and ethnic-related cognitive/academic achievement gaps continue to flagrantly ignore genetic ancestry. Not only do they ignore such results, but they also censor them. Thus, predictably, the published version of Guo, Lin, & Harris (2019) drops the results for non-Whites, along with Table 3 shown above, on reviewers’ insistence. Other researchers, who have looked at predictors of cognitive ability, have informed me that reviewers similarly have demanded PCs in place of more interpretable ancestry percentages and then, also, that the PC variables not be reported in the tables.
So, unsurprisingly Google Scholar yields just 48 hits, or two orders of magnitude fewer search results, for “genetic ancestry” and “achievement gaps.” But why? One has to suspect that our sociologists are not particularly interested in understanding the true cause of race/ethnic differences. Reality evasion continues unabated in academia.
References
Braudt, D., & Harris, K. M. (2020). Polygenic scores (pgss) in the national longitudinal study of adolescent to adult health (add health)–release 2.
Fryer, R. (2014). 21st-century inequality: The declining significance of discrimination. Issues in Science and Technology, 31(1), 27-32.
Fuerst, J. G. (2021). Robustness analysis of African genetic ancestry in admixture regression models of cognitive test scores. Mankind Quarterly, 62(2).
Giles, J. (2011) Social science lines up its biggest challenges. Nature, 470(7332):18–19.
Guo, G., Lin, M. J., & Harris, K. M. (2019). Socioeconomic and genomic roots of verbal ability. bioRxiv, 544411.
