Multivariate genetic analyses and simple correlational analyses have been conducted to evaluate the extent to which the general factor (g) of intelligence is differentially heritable, compared to, for example, group factors. A positive correlation would be supportive of Jensen’s view, notably advanced in The g Factor (1998), of the heritable g. This can be interpreted to say that what makes people good at all tests has more genetic component than what makes people good at one specific test. On the other hand, if environmental effects are smaller at the g level, it would mean that what makes people good at all tests has less environmental component than what makes people good at one specific test. Similarly, if heritability is large at the g level and the environment is small at the g level, then g differences between persons are largely genetic, not environmental (Plomin, 2003, p. 186).
The present article is a review of the studies published so far and can be seen as a complement to my article on the genetics of intelligence. Brody (2007) and Deary (2006) have already reviewed a large part of the existing studies. But some features need to be highlighted. The article can be subjected to modifications if I happen to read some more studies not listed here. Shortly, there seems to be some proof of differential heritabilities, higher for g. But it’s not overwhelming.
CONTENT
1) Review of the correlational studies.
2) Review of the multivariate genetic studies.
3) Caveat.
4) Going further.
__________________________________________________
1) Review of the correlational studies.
One meta-analysis of various twin studies reveals, using Jensen’s Method of Correlated Vectors (MCV), that the subtest g-loadings correlate positively with subtests heritability (h2) while being strongly negative for non-shared environmental (e2) loadings. The correlation between g-loadings and shared environmental (c2) loadings does not allow definitive conclusion due to the low reliability of c2 vector. Those studies also included adoption, sibling, or kinship/family studies and they reveal positive correlation between g and heritabilities. The studies having IQ batteries composed of mostly or exclusively verbal/crystallized subtests show positive but also negative correlations between g-loadings and heritabilities. Apparently, this disagreement may be explained by the small variance in g-loadings due to the homogeneous content of the test battery. Or perhaps the Jensen effect on h2 should not be expected when the tests are mostly culture-dependent. Furthermore, when the number of subtests is small, large disparity in size and direction of correlation is expected. That appears most likely, because other reports tend to confirm the positive r(g*h2).
My own analysis of the NLSY79 and NLSY97 reveals positive relationship between sibling (intraclass) correlations and g-loadings of the ASVAB subtests among black, hispanic, and white samples, although the expected positive correlation between black-white differences and sibling correlations were not clear at all. One caveat, however : the ASVAB can be suspected to be racially biased at the subtest level (Gibson, 1998). Even if the impact of bias has not been investigated at the test level, correlations may be different (although not necessarily so) if the subtests were unbiased.
Nichols (1970) studied a large sample of white (n=1940) and black (n=1460) siblings. He correlated the various (13) subtests g-loadings with subtest heritability among whites and among blacks as well as black-white subtest differences. All of these correlations were strong; around 0.60 and 0.80 between g and full sibling intraclass correlations (FS ICC), 0.85 between g and h2 estimates, 0.67 (or 0.60) between black-white difference and heritability (or FS ICC). Correlations between SES and heritability and black-white differences were also large and positive. This is supportive of the view that SES has a genetic component. Incidentally, Nichols (p. 121) argues that when SES is held constant, the correlation between BW difference and h2 is zero. On the other hand, when h2 is partialed out, the BW-SES correlation remains high. The author concludes that the BW difference is indexed by environmental rather than by genetic factors. But Nichols’ bad interpretation of partial correlations does not help his case. If SES has both genetic and environmental factors, h2 would be a portion (or subset) of whatever factors the SES variable measures. In other words, BW-h2 correlation may be expected to be zero when SES is held constant. A positive BW-SES correlation, with h2 constant, indicates that BW difference is a function of the environmental portion of SES and a null BW-h2, with SES constant, indicates that heritabilities are fully translated into SES differences so that removing the latter would reduce the former to zero. Such partial correlation attempts to examine the BW-SES correlation on the assumption that the subtests heritabilities are equal, while in reality they are not. Whatever relationship is found when h2 is partialed out, correlations can’t answer the question of whether (or not) the heritability in group differences created the SES differences in the first place.
Nagoshi & Johnson (1986) report similar results from the Hawaii Family Study of Cognition (HFSC). The sample includes the Americans of European Ancestry (AEA; 926 families) and the Americans of Japanese Ancestry (AJA; 368 families). The HFSC battery of cognitive tests include 15 subtests. The correlations between subtests g-loadings and sibling correlations, between g-loadings and parent-offspring correlations, are all positive. There were also some positive relationship between g-loadings and education/occupation attainment of either the parents or their children, g-loadings and spouse correlations, g-loadings and correlation between parental education/occupation status and offspring cognitive tests. The same relationship between g-loadings and SES measures was apparent in Nichols (1970) dissertation. Nagoshi & Johnson reported : “When parent-offspring resemblance on the cognitive tests is controlled for and the resulting partial correlations of parental education and occupation with offspring cognitive ability are used, the correlations with the g-loadings are reduced an average of 0.30, but a few still remain significant. If these environmental correlations are valid, it would indicate that the development of g is strongly influenced by the convergence of shared familial genetic and environmental factors, while non-g cognitive abilities are more under the influence of specific environmental factors.” (p. 206). The authors also investigate the correlation between g-loadings and mean within-sibship skews because “Such deviations from normality within a sibship would be reflective of such non-additive effects as directional genetic dominance, directional epistasis, directional GxE interaction, or directional non-additive environmental influences (Fisher, Immer and Tedin, 1932; Jinks and Fulker, 1970).” (p. 202). According to them, a negative correlation indicates that g is a fitness character that has been more highly selected for in the past than non-g, and a positive correlation would be indicative that g is more influenced by non-additive factors than is non-g. The correlations between g-loadings and mean within-sibship skews turned out to be close to zero (the r between g-loadings and absolute mean within-sibship skews was negative but it is to the fact that the use of “absolute” value would transform all negative r into positive r, thus creating spurious relationships). Spearman (rho) correlations produce similar results, i.e., such result was not due to outliers.
Subsequently, Johnson & Nagoshi (1990) analyzed the parental sibships (~70) of the HFSC. The correlation (corrected for unreliability) between g-loadings and biological uncles/aunts and nephew/nieces is r=0.29, rho=0.43, between g-loadings and unrelated uncles/aunts and nephew/nieces is r=0.26, rho=0.39, between g-loadings and cousins is r=0.71, rho=0.69. Thus, shared environment seems to have an impact that increases with g on this sample. But the size of correlations between unrelated persons and IQ subtests is generally so small that a positive r(g*c2) is inconsequential.
Those studies in general use the same kind of method as Jensen’s MCV. However Latent variable approach has the advantage of dealing with measurement errors and comparing models of 2nd-order latent g factor against models with only 1rst-order latent group factors.
2) Review of the multivariate genetic studies.
McClearn et al. (1997) report slightly higher heritability for PC1 compared to the short-form of the WAIS and to the cognitive dimensions formed by summing the subtests of Thurstone’s PMA battery. The speed factor is the only dimension that has a comparable h2 with the PC1. The reliability of IQ tests is high, generally speaking, so the higher h2 found in the g factor is probably not due to this kind of artifacts. The data is from the Swedish Twin Registry (STR), with 110 MZ and 130 DZ same-sex, and median age of 82.3 years.
Pedersen et al. (1985) discovered that DZ twins (N=34, aged 59, between 32 and 81) raised apart are more correlated in their g factor than among the cognitive dimensions (verbal, spatial, memory) of the IQ tests. Later, Pedersen et al. (1992) investigate the SATSA data of twins reared apart and together, aged 65.6, with 46 MZA, 67 MZT, 100 DZA, 89 DZT. The MZA intraclass correlation is an index of broad-sense heritability, and it was larger for PC1 (g) than any other subtests. They report a correlation between subtest g-loadings and heritability of about 0.77, after correction for subtest (un)reliability. Models with non-additive genetic influences were found to be more appropriate than models with additive genetic influences for PC1 and 5 of the 13 subtests. They note that “This result should not be overinterpreted to mean that all of the genetic variance is nonadditive, as the twin design has only modest power to discriminate the relative importance of Ga and Gd.” (p. 350) where Ga and Gd stand for genetic additive and genetic dominance (i.e., non-additive). Compared to non-shared environment, the genetic variances were stronger for Verbal-Crystallized and Perceptual Speed dimension but not on the Spatial-Fluid factor. And Memory is more influenced by e2 than by h2. Pedersen et al. (1994, Table 2) finally report for the SATSA the variance of each test having genetic and shared/non-shared environment effects unique to the subtests and common with the general factor. These genetic variances unique to subtests were smaller (especially in subtests having more g-loadings) than the genetic variances common with g, whereas it was just the reverse for non-shared environmental (e2) influences. So, there was evidence of genetic effects independent of g, but of smaller magnitude than those related to g. Plomin et al. (1994) also use the SATSA sample, and noted that the heritability of g was 0.80, whereas h2 ranges from 0.33 to 0.68 for the individual subtests. The average heritabilities are about 0.60 for verbal tests, 0.50 for spatial and speed-of-processing tests, and 0.40 for memory tests.
On a sample of 148 MZ and 135 DZ twins (around 9 years-old, ranging from 6 to 13 years) taking the SCA, and 141 MZ and 129 DZ taking the WISC-R, from the Western Reserve Twin Project (WRTP), Luo et al. (1994) used CFA-based analyses to evaluate the model fit of hierarchical g models between full models and reduced models where general and/or group factors are set to be zero (i.e., non-existent). When the g factor loadings are constrained to be zero, for the SCA, the model with no genetic (h2) g has worse fit than the model with no shared environment (c2) g, which has a worse fit than the model with no unshared environment (e2) g, whereas for WISC-R, the absence of “c2 g” has worse fit than “h2 g” which has worse fit than “e2 g”. This suggests that the genetic g factor is the more salient component in SCA while the shared environment g factor is the more important for WISC-R. But when the (second-order) g and group factor loadings are constrained to be zero, for both SCA and WISC-R, the removal of “h2 g” causes a worse fit than either a removal of “c2 g” or “e2 g” and these two environmental g seem to be almost equally important in achieving better fit. In other words, the “genetic” g+group model fits better than the “environment” g+group model. When these two models (general vs group factor loadings) are compared, the removal of h2 causes worse decrement than removal of c2, and this indicates that h2 is more important than c2 at the level of (first-order) group factors. Also, when all e2 parameters are constrained to be zero, the worsening of the fit (compared to the full model) is larger than the model where all h2 parameters have a value of zero. Again, this suggests h2 is more important than e2. The reason why WISC-R shows larger c2 effects may be because SCA taps more non-verbal abilities, which are suspected to be less affected by environmental and cultural effects. The weakness of that study may be that it uses only the Chi-Square. A final analysis involves Jensen’s MCV technique. They found that genetic g-loadings correlate strongly with phenotypic g loadings in both tests, whereas shared environmental g-loadings correlate less with phenotypic g loadings in both tests, and non-shared environmental g-loadings have strong negative (or positive) correlation with phenotypic g-loadings in SCA (or WISC-R). Generally, the authors believe that SCA better approximates genetic g than WISC-R.
Thompson et al. (1991) also use the same data, the same cognitive battery SCA but also add the MAT (Metropolitan Achievement Test). They summed the SCA (verbal, spatial, speed, memory) subtests to form 4 composite scores, representing different cognitive domains. The MAT has 3 standardized scores (reading, math, language). Among the SCA variables, the genetic correlations (rG) were high but the shared (rC) and non-shared environmental (rE) correlations close to zero. Among the MAT variables, the rG and rC were close to unity whereas rE were of modest size. The pattern of correlations between the SCA and MAT variables shows that rG are high (0.61-0.80) whereas rC and rE are very low, except Speed for which the rC with MAT variables are close to 100% although the authors believe “these results are artifacts of the near-zero effect of common environment on perceptual speed”. Their appendix table shows that loadings of all these 7 variables on genetic g are high, whereas the loadings on non-shared environmental g are close to zero. The loadings on shared-environmental g are close to zero for the 4 SCA variables but very high for the 3 MAT variables. This suggests no general factor for c2 on this entire battery. Given these figures, attempts to fit the c2 structure to a (first-order) general factor model will undoubtedly deteriorate the fit.
Petrill et al. (1996, Tables 5 & 7) analyze the same sample of WRTP (135 MZ and 128 DZ), with the same 11 subtests of the WISC, but they have included the 6 ECTs from the Cognitive Abilities Test (CAT) in their model to be tested. It contains 4 first-order group factors, verbal, performance, freedom from distractibility, speed, and a 2nd-order g factor. When the genetic distractibility factor has been dropped, it resulted in better model fit. This was because, apparently, this factor shares no genetic variance with the other factors, i.e., genetic effects that help to score better on the subtests belonging to this factor are different from those that help to score better on the subtests belonging to other factors. The shared environmental loadings on g were much stronger than the genetic loadings on g whereas it was the reverse for the loadings on the group factors. The general factor was almost sufficient to account for all of the c2 variance whereas h2 needs both general and group factors. Interestingly, the c2 loadings on g was stronger on the WISC subtests, especially the crystallized (verbal) subtests, whereas the h2 loadings on g were stronger for the CAT variables while h2 loadings on g for these crystallized WISC subtests were close to zero. A good indication that the crystallized subtests do not share much genetic variance in common with the subtests that do not belong to the Verbal group factor. Thus, one may wonder what model(s) will emerge as the best fit if all of the subtests measure essentially less-culturally dependent abilities.
Part of the answer might have been provided by Luciano et al. (2004). The twins were drawn from 3 separate survey data, the Netherlands Twin Registry, the Brisbane Adolescent Twin Registry, and the Keio Twin Registry. They were aged 16 on average. The total N pairs was 543, with 129 MZF, 116 MZM, 75 DZF, 69 DZM, 154 DZ opposite sex. The given tests were 3 verbal and 2 performance (timed) subtests of the MAB battery collapsed into VIQ and PIQ, as well as inspection time (IT), choice reaction time (2-, 4-, 8-CRT), and a delayed response (DR) task composed of initiation time, movement time, and winnings. A total of 9 tests. Since the MAB was speeded, it also measures a speed factor. Luciano uses a Cholesky approach. In its essence, the method specifies as many factors as there are variables for each source of variance (h2, c2, e2), each factor having one loading less than the previous one (i.e., the first genetic A1 factor loads on all variables, the A2 loads on all variables except the first, and so on). The c2 parameters were probably close to zero because when they dropped the C from the ACE Cholesky decomposition model, the fit did not change at all. When they fit a genetic model with h2 general factor, group factors and specifics, and E Cholesky, the model fit worsened (compared to the AE Cholesky model). The final model retained was a reduced AE Cholesky (in which some of the A and E paths toward the subtest variables are removed). The first genetic factor (A1) has a non-zero loading on all variables (strongest with IT) except for DR movement time, the second genetic factor (A2) loads on all variables except IT, the third genetic factor (A3) loads on 4-CRT, 8-CRT, VIQ, PIQ, and the other genetic factors have either one of two loading(s). Undoubtedly, A1 is the general factor, and A3 may represent a group factor reflecting processes related to choice decision, but what is A2 in this case ? According to the authors, “Because IT was the only task not requiring a speeded response, we theorised that this factor reflects those individual differences (e.g., anxiety, motivation, decision processes, strategy use) that influence performance under timed conditions.” (p. 86). The authors interpret A1 as follows, “Because IT is considered to be a purer measure of information processing speed than CRT, which is confounded with motor response, the first factor was theorised to represent a processing speed property of the brain that determines the efficiency or speed of very basic information processes, such as fine visual discrimination or encoding.” (p. 85). The fact that E factors have either single or multiple loadings indicates that e2 fits the model when we assume that e2 exerts its influence at the group factor and specific level, but not on the g level. This study contrasts with Petrill (1996) because the cognitive battery used by Luciano is dominated by less-culture dependent tests, i.e., 7 ECTs and 2 psychometric tests. Perhaps another explanation is the sample age (16 vs 9). Perhaps one problem with the study is the test administration of the MAB, because the participants were encouraged to guess and answer every question.
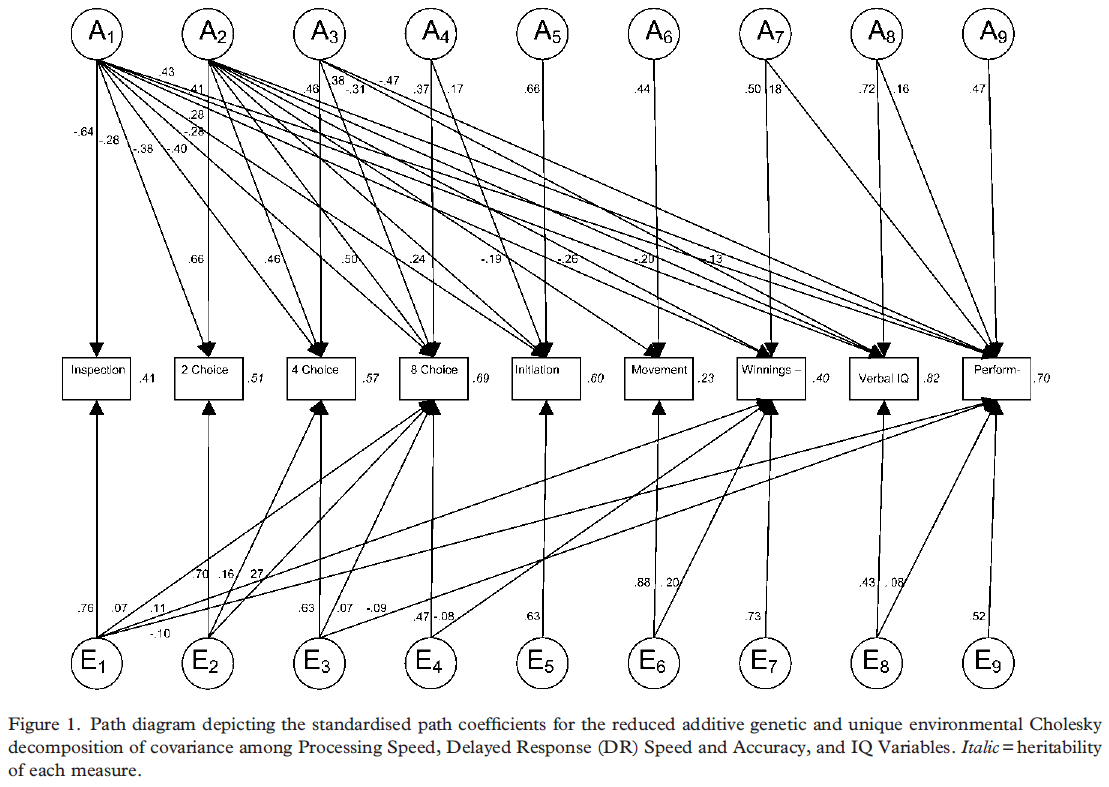
Bergeman et al. (1988) analyzed a sample of adoptive (n=196 at age 3; n=177 at age 4) and control (n=189 at age 3; n=161 at age 4) children from the Colorado Adoption Project (CAP). They try to fit a path model of genetic and environmental transmission to general IQ and specific cognitive ability data, from biological, adoptive and control (nonadoptive) parents and their children at ages 3 and 4. More precisely, the impact of parents’ (mother and father) phenotype on the child’s environment and genes. The hypothesis of a stronger heritability for g is not well evidenced in that sample. At both age 3 and 4, the general factor (PC1) has comparable heritability with spatial factor. Verbal has comparable heritability with g at age 3 but not at age 4. Perceptual speed and memory have lower heritability in both ages. The heritability of memory is close to zero. Perhaps the mixed evidence for genetic g is due to the young age of the children.
Rice et al. (1989) also analyze the CAP with 4 years-old children, 151 adopted and 135 non-adopted, with their biological and adoptive parents. The 13 subtests are averaged to form 4 scale scores, verbal, spatial, speed, memory. The large genetic correlations (average rG=0.60) between these dimensions suggest, according to the authors, that genetic transmission of specific cognitive abilities may involve general intelligence. By way of comparison, the environmental correlations were generally smaller (average rE=0.26). And the maternal cultural transmission was also of weak magnitude. Both the parameters for father and mother cultural transmission, as well as (passive) GE correlation, could be removed (i.e., fixed at zero) from the model without worsening the fit in the model.
Cardon et al. (1992, Table 2) also modeled a hierarchical genetic and environmental g, using the SCA test. There were 196 adopted and 213 non-adopted children, 52 unrelated siblings of the adopted probands and 68 natural siblings of the control children, from the CAP data. The children were aged 7.4. Removing the genetic g causes substantial decrement in fit (104.56 χ²), much higher than that found for shared (2.46 χ²) and non-shared (19.56 χ²) environmental g. However, removing the group factors causes a greater fit decrement for genetic loadings (124.94 χ²), but not shared (1.76 χ²) and non-shared (2.22 χ²) environmental loadings where the decrement is very small. In other words, genetic influences operate at both the 2nd-order g and 1rst-order group factors although these genetic effects on genetic group factor(s) were stronger than on genetic g. This can be seen in their Figure 3 and Table 2. This is mostly due to Verbal and Memory group factors having very large genetic residuals (i.e., unique genetic effects not shared with the other factors through the 2nd-order g factor). Note that Speed has a very large loading on genetic g and its genetic residual is zero. Since removal of c2 influences did not cause large fit decrements, the authors estimated their final model (Figure 3) with only h2 and e2 specifications. We can see that e2 has only its influences at the (first-order) g level but this should not be over-stated. From their table 2, only Speed and Memory have substantial loadings on the non-shared environmental group factor. That is why in their Figure 3, only the subtests of Speed and Memory have loadings on this so-called first-order non-shared environmental g. On the other hand, h2 have influences on IQ at the g and group factor(s) level (the Speed group factor is absent because it has zero genetic residuals due to the fact that Speed loads entirely on genetic g). The reason why the 2nd-order genetic g was needed is simply because the group factors are all genetically correlated, thus an indication of a shared genetic variance.

Alarcón et al. (1998) extend the works of Cardon et al. (1992) on the CAP. The children were aged 12 (N=175 adoptees, N=209 non-adopted children). They report higher heritabilities than those noticed by Rice et al. (1986, 1989). The similarity of the 6 genetic correlations among the 4 cognitive factors is suggested by the non-significant change in χ² after these correlations were set to be equal. As a result of this specification, all genetic correlations were at 0.483 in the reduced model. When the genetic correlations were fixed to be zero, there was a change in χ². In comparison, some of the environmental correlations were of similar magnitude but 3 of them were relatively small. They conclude their findings are coherent with the hypothesis that h2 increases with age. This figure can’t be due to larger reliability found at larger ages that would cause an artificial increase in h2 with age, because reliabilities at age 4 and age 12 were very similar (0.67 and 0.70). Of course, for an IQ test, this number is too small to be acceptable. As in previous reports, parental (mother and father) cultural transmission and passive GE correlations appear to be weak (m, f, and s parameters in Table 3). Alarcón et al. (1999) published a follow-up analysis on these same children, aged 16 years. The rG averaged 0.541, not higher than the 4-years-old children reported in Rice et al. (1989).
Petrill et al. (1998) use similar techniques on a sample of 82.7 (mean) yrs old twins from the Swedish Twin Registry (STR); 52 MZ and 65 DZ twins. The IQ subtests were similar to those used by Cardon. The battery consists of 7 subtests, with 4 scale scores, and a first-order g factor. Compared to the full model, the χ² increment was the largest for the “no genetic influence” (90.84 χ²) specification, i.e., genetic loadings seem largely to be different from zero. The general genetic (74.36 χ²) seems more important than specific genetic influences (70.91 χ²), as judged either by χ² decrement or by Akaike. The “no shared environmental influence” specification causes a χ² decrement of 67.68 with p-value of 0.18, which is non-significant, but based on this small sample, that is not surprising. The h2 loading on g is high, and e2 loading(s) on g modest but smaller than on the specific tests. The h2 loadings on the specific tests are modest. The c2 loading is zero for g and scale scores, except verbal.
In a similar vein, Davis et al. (2009) examine the sample of the TEDS (1945 MZ, 1760 DZ same-sex, 1729 DZ opposite-sex) who took, at age 12, a total of 14 tests. They were used to form a correlated factors model with 4 latent factors, reading, math, language, and g (which is measured using vocabulary, general knowledge, picture completion and Raven’s test). The genetic correlations between these 4 latent factors range between 0.75 and 0.91, whereas the (shared) environmental correlations were all very close to 100%. It seems a genetic model using the 2nd-order g structure would fit well, and could have been compared with a genetic model using this 4-correlated factors.
Finkel et al. (1995, Table 6) compare the Minnesota Twin Study of Adult Development and Aging (MTSADA) and the Swedish Adoption/Twin Study of Aging (SATSA). The MTSADA has 191 participants and SATSA has 206 participants; each sample was decomposed into 3 age categories, 40yrs, 60 yrs, 70yrs, and each sample was given 4 of the WAIS subtests, Information, Block Design, Digit Symbol, Digit Span. Each representing a different cognitive area, i.e., verbal, spatial, perceptual speed, memory, respectively. When they dropped the shared environment (c2) the model fit improved. This is strong evidence that c2 was truly non-important. The best fit model was one including heritability (h2) and non-shared environment (e2). In the MTSADA full sample, h2 seems a little bit stronger for the specific factor while e2 is much stronger for specific factors. In the SATSA 40-60 years combined, h2 is just a little bit stronger for the general factor while e2 is more substantial in specific factors. In the SATSA 70 years, there is no strong evidence that either the specific or general factor was more important than the other for either h2 or e2. Not only the genetic g model is not supported, but the pattern and relative strength of the general and specific genetic loadings for each subtests do not show any concordance among the samples; e.g., some subtests show large general genetic effects in one sample but not in the other. One explanation is the test version used, according to Finkel, “the Digit Symbol tasks are not identical in each study. WAIS-R Digit Symbol involves writing unusual symbols by an array of digits, while the Swedish Digit Symbol task involves writing known digits by an array of unusual symbols.” (p. 430).
LaBuda et al. (1987) examined a sample of 37 MZ and 33 DZ in which at least one member of each pair was reading disabled with another sample serving as a control group consisting of 42 MZ and 31 DZ pairs, mean age 12.5 years. The IQ battery is WISC-R. One of the models (n°7) imposed a general factor on the genetic matrix but has worse fit than the model (n°8) that imposes a three-group factor model (the so-called Kaufman structure) on the genetic matrix. Shifting from 1rst-order genetic g to group genetic factor model was the most appropriate specification.
Tambs et al. (1986, Table 5) found evidence for a larger heritability in the 3 common (rotated with Varimax) factors derived from 11 WAIS subtests using factor analysis. These factors were Verbal Comprehension, Freedom from Distractibility, Perceptual Organization. The sample is composed of 40 MZT and 40 DZT, mean age 40-42. Heritability was much stronger for common factors than for specific factors. And while shared environment is stronger for common factors, the non-shared environment is stronger for specific factors. Casto et al. (1995, Table 8) applied a similar procedure as that of Tambs (1986) on the WISC-R. The sample is composed of 135 MZ and 87 DZ control twins, 197 MZ and 155 DZ twin in which at least one member of each pair had a school history of reading problems; mean age was 11.24 years. Unlike Tambs, their 3 factors were not derived from factor analysis, but only obtained by summing the subtests. Genetic influences seem to be stronger on the specific subtests rather than on the common factors. An evaluation of the covariance structure reveals that in a model where specific factors were hypothesized to account for all the genetic variance, there was a large fit decrement. On the other hand, when a single factor is assumed to account for all the genetic variance, a large fit decrement was also observed. Again, both common and specific genetic factors were needed. The importance of a shared environment seems to be similar at the specific and common factor level. Both the heritability and non-shared environment were stronger for specific factors, not common factors. So, while the “genetic g” model seems to be the more appropriate in Tambs, it was not in this study. Perhaps the difference is due to the younger age of the sample or due to the particularity of the sample having children with reading problems. Unless the outlier was the Tambs study.
Rijsdijk et al. (2002) rightly noted that these 2 studies have not tested the general genetic factor model explicitly by modeling the 2nd-order g factor above the 1rst-order group factors. Rijsdijk analyzed the Dutch twin longitudinal project, (N=194, mean age = 16.13 yrs). The subjects took the WAIS and the Raven matrices (without time limit). In the best fitted model of hierarchical second-order general genetic g, the c2 structure was omitted because there was no deterioration in model fit (p-value=0.99). They argue it is probably because of the older age of the sample, compared to other studies of younger children. The 2nd-order g was also omitted for e2 because the environmental loadings on the 1rst-order group factors were very low. According to the authors, the high genetic correlation among subtests loading on different scales would suggest the presence of a general genetic factor influencing all subtests. Given their Table 7, and for genetic effects, the 2nd-order general factor was more important than either the 1rst-order group factors or the specific factors, whereas for non-shared environmental effects, the loadings in the 1rst-order g factor were very low but high for specific factors. Finally, the covariance of the Raven test score with the WAIS subtests was largely accounted for by the general 2nd-order genetic factor. Here, the genetic g model was well supported.

Wainwright et al. (2005b, Table 3) analyze the Brisbane Memory, Attention and Problem Solving (MAPS) twin study, having 182 MZ and 208 DZ, and an additional sample of 81 single twins. Mean age = 17.3 years. The subjects are given the Queensland Core Skills Test (QCST) which is an achievement test, composed of 5 scores. Two IQ scales, Verbal IQ and Performance IQ, were from the 3 verbal and 2 performance/spatial subtests of the Multidimensional Aptitude Battery (MAB). In total, 7 tests were investigated. They discovered that the proportions of phenotypic correlations between the tests/subtests were largely accounted for by genetic influences, with PIQ having proportions near 100%. Perhaps one weakness of the study is that the cognitive tests were mostly achievement tests, not IQ tests. Mosing et al. (2012) administered the VESPARCH-1 (2 verbal and 2 spatial tests) to 338 twins, from the Brisbane Longitudinal Twin Studies (BLTS). All were aged 12. The best model was one that posits a common genetic factor to all tests, no c2, and specific e2. The genetic correlations between the 4 subtests range from 90% to 100%.
Luciano et al. (2003, Table 6) studied the MAPS data as well (total N=390; for 97 MZ females, 87 MZ males, 52 DZ females, 48 DZ males, 106 DZ opposite sex pairs; mean age 16.17 yrs). They use 3 verbal (Information, Vocabulary, Arithmetic) and 2 performance (Spatial and Object Assembly) subtests of the MAB battery as well as the Digit Symbol of the WAIS-R. Thus, only 2 cognitive domains were modeled, and that might explain why a phenotypic model of “general factor + specifics” appears not to have the best fit. Instead, it was a “two oblique group factors + specifics”. Then the genetic models show the best fit model was one with genetic 2-oblique factors + specifics, c2 general factor, and e2 Cholesky. The genetic verbal and performance factors correlate at 0.47, which is largely different from 1.00 but not surprising, and even the authors noted in this regard, “Subtests for our study were selected so that maximal differentiation of verbal and performance abilities was attained, and hence it was not surprising that the correlation between genetic factors was of moderate size.” (p. 601). They also suspect that Digit Symbol has larger specific genetic effects because it has a better factor loading on Freedom from Distraction factor rather than on the Performance factor in the WAIS-R analyses. In general, additive genetic effects were substantially larger than common environmental effects for all measures, except for Arithmetic where they were equal. They argue that c2 variation is more general than specific but they also write : “Eaves, Heath, and Martin (1984) interpret general common environmental influences in terms of a generalized effect of assortative mating (which is confounded with common environment in the classical twin design). They propose that individuals select mates on a general rather than specific latent factor, which may be general intelligence or correlated factors, such as educational achievement or socioeconomic background. The general factor is a linear combination of the additive effects of each specific cognitive ability, and this explains why the common environmental variation is general rather than specific.” (p. 602). Although the authors recognize that their model indirectly implies a general genetic factor, this battery seems not ideal to directly test the genetic g model. Finally, in commenting on the conflicting results from Casto and Tambs, Luciano stated that the difference can be explained by the fact that the pleiotropic effects of genes on cognitive abilities develop with age.
Similar findings were previously reported by Rietveld et al. (2000) who analyzed the Netherlands Twin Register (209 pairs; 47 MZF, 37 DZF, 42 MZM, 44 DZM, 39 pairs of opposite sex (DOS); mean age 5yrs). They were given 6 subtests (3 verbal, 3 non-verbal) of the RAKIT battery. As expected, the best fitted model was one which hypothesizes a general shared environmental factor, a specific unique environment factor, and a two-group genetic factor(s) as well as genetic specific(s) for verbal and non-verbal. These two group genetic factors don’t correlate with each other. The independent effect of genes on cognitive abilities found in this study is not in line with some others.
Johnson et al. (2007) studied the Minnesota Study of Twins Reared Apart (MISTRA) data. There were 126 twin pairs reared apart, (74 MZ and 52 DZ). Mean age was 42.7yrs. They were all given the Comprehensive Ability Battery (CAB), as well as Hawaii Battery, including Raven’s progressive matrices (HB), and the Wechsler Adult Intelligence Scale (WAIS); for 14, 17, and 11 subtests, respectively (total=42). They demonstrate that there are non-trivial genetic residuals (variances due to fourth-stratum g, third-stratum factors, and second-stratum factors, removed) in each of the 42 subtests, although much less than the environmental residuals. A comparison with the saturated (full) model shows that the model with 2nd-order factors, with the 4th-order g factor, and with the 3rd-order factors do not significantly differ from the saturated model (p. 553). In the model with 4th-order g factor, the genetic and environmental variance were 0.77 and 0.23. The numbers were very similar for the 3rd-order factors model. The genetic variance in the 2nd-order factors model turns around 0.67 and 0.79, except for Content Memory for which the genetic variance is only 0.33. While h2 is substantial at the g level, there is no evidence that h2 increases at each subsequent stratum. Finally, the authors noticed (Table 9) that shared environmental effects do not meaningfully affect IQ, although the home quality was superior for adoptive rearing.
3) Caveat.
Some problems related to almost all of the multivariate genetic studies is that model selection and comparison are based on the old-fashioned χ² statistics, known to be extremely sensitive to sample size. Even “χ² change” value is subjected to the same problem. With small samples, the χ² change is small, and large when sample is large. In the framework of latent variable approach, the best model to be retained, traditionally, requires that the non-significant free parameters (i.e., those freely estimated by the model) to be fixed to zero, thus increasing the degrees of freedom, which makes the model being more parsimonious. In fact, the goal of the selection of the parameters to be fixed at zero (i.e., removed) or freely estimated is to build the most parsimonious model possible, without (significant) model fit decrement. But choosing which parameters should be dropped depending on statistical significance would lead to type 2 error (false negative) if the sample is small. For example, when Walhovd & Fjell (2007, Figure 3) dropped the non-significant paths, the path correlations with the smallest magnitude are removed, but among them, there was a path correlation of r=0.23, which is obviously very different from zero, but not according to significance tests.
If we were to evaluate the relative importance of a model’s parameters, significance tests can provide an index of effect size. But if we were to choose which one is not different from zero, we are doing something wrong. When researchers report the size of the correlations before they are dropped (if they are any) some useful information is provided, but when they are not reported, there is no way to know if they are committing type 2 errors.
Another but related problem with these studies is that when they estimate h2, c2, and e2, these are variance-based effect sizes. I have already explained why R² is not appropriate. The h2, c2, and e2 must be square rooted. And the relative importance of the impact of h2 over c2 and e2 would obviously diminish.
4) Going further.
All these studies, whether they use MCV or multivariate latent variable(s) methods, indicate that when shared environment (c2) effect is different from zero, it has its effect on the general factor of intelligence. When c2 effect does not show up, the general belief among the authors was that the subjects were either adolescent or adult. Based on multivariate genetic studies, there seems to be no doubt that c2 affects the general factor, but the magnitude of the stimulation due to familial environment is suspected to be small. A positive relationship between g and c2 should not be taken as a proof that c2 has an important effect on g. Based on MCV, sometimes we find that there exists a positive, but modest r(g*c2). The positive r(g*c2) only means that the small effect of c2 on IQ increases when IQ becomes more complex or tends to elicit more general abilities. The conclusion that c2 and h2 have equal importance on g just because their respective correlation with g are equal is unfounded. The size of the correlation with each subtests must be examined first. And based on MCV, a large portion of the correlations between c2 and IQ subtests is close to zero.
Given what is said above, even the question about differential heritabilities is not necessarily troublesome for the hereditarian hypothesis. A high heritability in IQ despite a null r(g*h2) may be a problem, but only for the “genetic g” theorists. The higher heritability of g is sometimes supported, but not always. The composition of the IQ battery seems to matter (Luo, 1994; Petrill, 1996; Luciano, 2004). In the Luciano study, while the c2 parameters were not significantly different from zero, they noticed that c2 has some modest effect on verbal IQ, and in the Petrill study, the crystallized subtests of the WISC have loadings on the general genetic factor close to zero. For the WRTP data, twins aged 9 years, Thompson et al. (1991) estimated a large shared environmental influence but low heritability for achievement tests (the MAT) and large heritability but low shared environmental influence for cognitive ability tests (the SCA). van Leeuwen et al. (2008, p. 86) also have similar suspicions about the (near)-absence of c2 when a fluid test such as Raven is used instead of a very crystallized one.
Pattern of genetic correlations can be affected the same way, as Wainwright et al. (2005a) would explain : “Additionally, it is notable that there was a significantly stronger genetic correlation between QCST and VIQ than between QCST and PIQ. This is presumably due to QCST items being weighted towards verbal (rather than performance) skills with genetic influences for both general cognitive ability and verbal ability exerting concomitant effects on QCST and VIQ. The lower genetic correlation between QCST and PIQ was due to their genetic overlap being solely via genetic influences for general cognitive ability.” (p. 142).
Hart et al. (2009) noticed similar artifacts. Reading and math abilities can be correlated genetically when both are timed but less so when they are not timed. That the genetic overlap increases due to the similarity in the ability components measured by the tests included in the battery is well illustrated by Hart et al. (2009), “There also appears to be a trend in that the younger twins suggested more shared environmental influences for math measures that were not timed and genetic influences for the timed math measure (Fluency). … This result suggests that the inclusion of RAN in the model results in an association between math fluency, and reading. This is not the case when RAN is not in the model, where math fluency appears to be more of an independent measure of ability. Math fluency is the only math measure presently tested with a timed component, which is similar to RAN being the only timed measure of reading ability. Perhaps it is this timed nature, rather than the actual computations, that make RAN and fluency similar to each other, reflected in the genetic overlap. In other words, it is the timed nature, not the actual specific skills, that results in genetic overlap.” (pp. 396-397). Definitely, the nature of the tests truly makes a difference.
The same problem seems to appear in the studies based on MCV. Cognitive batteries dominated by verbal tests show very disparate size and direction of correlations between g and h2. Sometimes, high, low, null, positive or negative.
An interesting finding is that memory is influenced more by specific genetic factors rather than by general genetic factors (Cardon et al., 1992; Pedersen et al., 1992; Finkel et al., 1995, Luo et al., 1994; Luciano et al., 2004; and to some extent, Johnson et al., 2007). There are some suggestions that these tasks are just too simple (Mayfield & Reynolds, 1997). The same reason, probably, for why memory has substantial specific genetic effects. If we were to correlate the cultural loadings of the (sub)tests with their heritabilities or g-loadings, these details must be taken into account. Or the result will be biased.
Speaking of bias, another worry is provided by Jacobs et al. (2001) study on chorion effect. MZ twins are mostly monochorionic (MC) rather than dichorionic (DC) while all DZ twins are dichorionic. The monozygotic of MC type share the same placenta during gestation thereby allowing the twins to exchange blood and all the biological influencing factors it may contain. So, heritability based on MC-MZ twins rather than DC-DZ twins can upward bias the heritability. But perhaps not homogeneously. For example, the subtests with mostly upward biased h² were Arithmetic and Vocabulary, incidentally one of the most g-loaded subtests of the Wechsler. Jacobs et al. (2001) also report previous studies of this kind and reveal that the Block Design subtest (the most g-loaded performance subtest on the Wechsler) shows more similarity for MC-MZ than for DC-MZ twins. However, this effect could not be replicated in a 3-year follow-up. Reports of other studies suggest that the chorion effect may vanish over time. On total IQ score, chorion effect seems rather weak, but its differential impact across subtests should not be ignored.
On the one hand, the plausibility of differential chorion effects resulting in larger upward bias on h2 estimates for crystallized subtests would tend to disprove Kan’s (2011) conclusion that heritability is stronger for more culturally loaded subtests, which would act to confound genetic g. On the other hand, it casts doubt on the plausibility that g-loadings would be positively related to h2 on the Wechsler. But even worse is that we may not know exactly how chorion effect would differentially impact heritability estimates on other test batteries, not only at different subtests but also at different ages. This casts doubt on MCV but also on multivariate genetic analyses since they had to work on some differentially biased cross-twin covariances. If the chorion effect really disappears over time, this suggests that MCV and other techniques must preferably use adult data.
The g factor (of intelligence) is not only the ability to perform better at all other (IQ) tests but also the ability to deal with complexity. A more demanding, complex test is expected to show higher heritability, according to the genetic g model. Beaujean (2005) conducted a meta-analysis on ECT studies, and estimated a larger heritability for the more complex ECTs, a broad heritability of 0.50. Shared environmental influences, as expected, diminish with RT complexity. The h2 of 0.50 in ECTs seems lower than h2 in IQ tests but Jensen (2006, p. 133) advances the idea it was due to the narrower cognitive domain measured by ECTs as well as their lower reliability.
The mutualism model formulated by van der Maas et al. (2006) and proposed by Kan (2011, p. 91) as well may account for this pattern of genetic correlations between tests/subtests. The mutualism can be illustrated as follows :
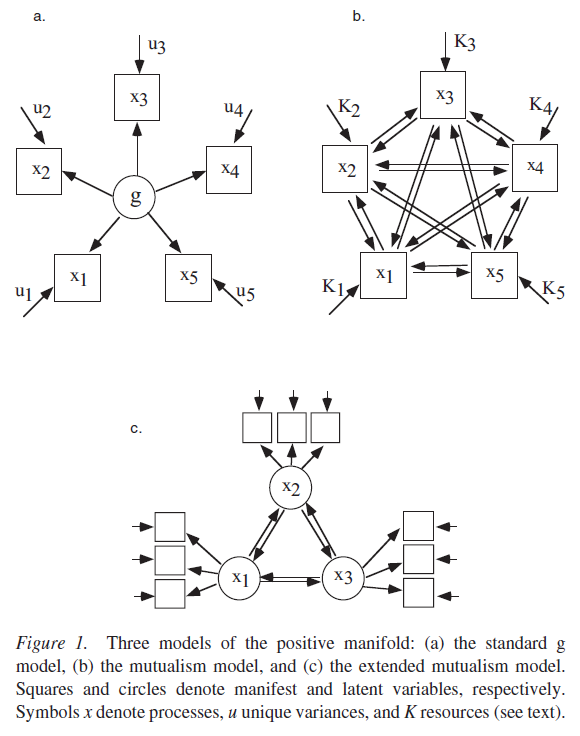
It hypothesizes that g is not a latent, causal factor but instead, is an emergent factor. When the resources “K” act on some specific ability, it will trigger a positive cycle of reciprocal causation, with each ability positively affecting each one and re-inforcing themselves by the same occasion. Like in the Dickens & Flynn (2001) model, environment magnifies genotype. van der Maas argues “Note that the average or sum of uncorrelated K is not a common factor, in the factor analytic sense (i.e., a single underlying variable). For instance, one person’s high performance on cognitive tasks may be due to exceptionally high Ki for certain processes (e.g., memory processes), another person’s high performance may be due to high Ki for completely other processes (e.g., language processes), and a third person’s high performance might be due to the general absence of low Ki. This differs fundamentally from the g explanation of individual differences in which similar performance is due to similar g value. This g explanation leads to the expectation that we should be able to find some (presumably biological) factor equal to g (Bartholomew, 2004). Failure to find such a factor supports alternative approaches, for example, the mutualism model.” (p. 848). And later, “the increase in heritability during development can be explained by assuming that uncorrelated limited resources are (partly) genetically based, whereas the growth parameters are not, or are genetically based to a lesser degree.” (p. 854). In the mutualism framework, intercorrelations should increase with age, as well as the genetic correlations between the tests. These genetic factors strengthen the stability of g over the development.
The problem is whether the mutualism model predicts a low genetic correlation among cognitive domains. van der Maas posits weak correlation at early ages. Rietveld (2000) indeed found no relationship at all between the verbal and non-verbal factors of the RAKIT on a sample of 5-yrs-old children. This is probably an outlier. The large genetic correlations (mean rG=0.73) reported by Rice (1986) on the CAP data among 4-yrs-old children, although the mean rG was 0.60 in Rice et al. (1989), suggest that even at this age, the cognitive factors are clearly not independent, even if they do indeed increase with age. Such large correlations appear problematic for the mutualism. In Thompson et al. (1991) the mean rG of the same kind of tests was 0.62 among 10 yrs-old twins in the WRTP. Martin & Eaves (1977) examine Loehlin and Vandenberg (1968) twin study, the 5 subtests of Thurstone’s Primary Mental Abilities, and the mean rG is 0.58. I was unable to find the original reference but Plomin et al. (2013, p. 217) mentioned they were adults. At age 2, however, the genetic correlations can be lower, as in Petrill et al. (2001) from the TEDS sample, where the mean genetic correlation between the non-verbal subtests of the PARCA is 0.30 while the shared environmental correlations were stronger (0.44). But still, the pleiotropic effects of genes on IQ are modest, not independent. If we were to drop these genetic paths from the model, the fit will drop. Similarly, Price et al. (2000) use the same data, same aged children, and use the non-verbal PARCA as well as the verbal MacArthur (M)CDI. They report an rG of 0.30 between them. Hayiou-Thomas et al. (2006) use a sub-sample of the TEDS and report high rG between several language tests (mean 0.58) and latent factors (0.64) for the 4 1/2 years-olds. Lemelin et al. (2007) report an rG of 0.77 between latent factors of school readiness and school achievement on children aged 5. Even the Hoekstra study (2007, Table 9) cited by Kan (2011) as illustrative of the mutualism model only shows a modest increase in rG between verbal and non-verbal abilities between age 5 and 18 (from ~0.60 to ~0.70). Again, if the mutualism depends on a strong increase in rG from childhood to adulthood, this assumption of the model is weakened by the Hoekstra study. By way of comparison, the Davis (2009) study shows genetic correlations averaging 0.85, a big jump compared to Petrill and Price (but not Hayiou-Thomas), except for the fact the cognitive dimensions measured were different. Another data, although smaller, is informative; Rice (1989) and Alarcón (1999) use the CAP with the same measured ability dimensions, and the mean rG for the 4- and 16-years olds were, respectively, 0.60 and 0.54.
Also troubling is Thompson et al. (1985) study of the CAP among infants (12 and 24 months). The Bayley Scale (MDI) scores of the 24-months (non-adopted) infants show low to modest correlation with their biological parents specific abilities, probably due to low reliability of infant measures, but some of these correlations diminish substantially when parents’ general intelligence is partialed out. The infant IQs were in fact more correlated with the g factor of their parents than with their test score residuals (i.e., specific abilities). Similar conclusion was apparent for biological parents with their adopted-away infants. By way of comparison, the adopted infants’ IQ show low correlation with their adopted parents ‘specific abilities but no correlation at all with their g factor. Biological parents and their offspring share genes but not the adopted parents with the adopted children who share only family environments. The existence of a genetic g even at this early state of life is an indication that g is not an emergent factor. Thus, the correlation between the tests are not genetically independent. The mutualistic relationship between genetic and environmental factors, following the mutualism model, cannot be expected to give rise to (genetic) g if environmental influences cannot have causal effects among infants (McCall, 1981, p. 8).
But more problematic for the model is that Shikishima et al. (2009) as well as Panizzon et al. (2014) found evidence of causal g. The environmental and genetic factors influencing the cognitive factors were mediated through a general latent factor, g. van der Maas expects the mutualistic process to cause an increase in the strength of (sub)tests intercorrelations (i.e., manifold) over ages. But when Gignac (2014) attempted to confirm the said prediction, starting from age 2 to age 90, using the Wechsler’s scale, it appears that the mutualism fails the empirical test. Not only the increase in the strength of the manifold is tiny, but these intercorrelations were already very high even at ages 2-5 (the sample who took the WPPSI) with an ωh (ratio of true score variance to total variance) as high as 0.80.
Empirically, it would seem that the alternative models to the traditional g don’t hold water (Dalliard, 2013). The g factor is best seen as a causal entity.
Despite these problems, Kan (2011) interprets the positive correlations between g-loadings, heritability, and cultural loadings by way of GE correlations. To this matter, the Cardon (1992) study is one of the most informative. From their table 2, we see that among all the group factors, Verbal has the highest heritability (0.90), which the author calculates by adding the square of Verbal genetic loading on g and its residual genetic loading, i.e., 0.46^2+0.83^2=0.90. In other words, h2 has two components, one is the genetic influence incorported in g, the other is the genetic influence independent of g. Now, Speed factor, assumingly less culturally dependent than Verbal, has h2=0.76. At first glance, this is coherent with Kan’s story. But there is something else. The loadings of Verbal and Speed on the genetic g are 0.46 and 0.87, respectively. That indicates Speed shares more genetic variance with the other factors. Stated otherwise, Speed approximates genetic (2nd-order) g much better than Verbal. And similar conclusion can be inferred from the Petrill (1996) study as well. The variables having the highest loadings on the 2nd-order genetic g are those that are clearly less culturally dependent (e.g., ECTs). Rijsdijk (2002, Figure 1) tells the same story, with the Raven first-order group factor having similar (in fact, higher) genetic loading on 2nd-order g than the first-order verbal group factor on 2nd-order g. One curious finding comes from Cardon & Fulker (1993, p. 112). They report the loadings of these four ability factors (V, S, P, M) on the 2nd-order genetic g for ages 3, 4, 7, and 9, but they appear to vary greatly over age with no coherent pattern. Part of the explanation is that they have combined the CAP, MALTS and TIP data which use different subtest data. One may need a general picture. This is what Petrill (2002, pp. 290-292) proposed. Gathering several data, he summarizes the % of total variance in verbal, spatial, speed, memory, accounted for by general genetic variance (but not necessarily a second-order g and not on the same test battery). It appears that Verbal and Spatial have more or less equal shared genetic variance, while the Speed had the most shared genetic variance, and Memory by far the least. Plomin et al. (2013, pp. 213-214) reported other and older data, e.g., the 15-30 studies summarized in Nichols (1978), but it does not seem that Verbal was more heritable than either Spatial or Speed. It was the opposite. And finally, unless reaction time becomes more culturally dependent with its complexity, the positive relationship between RT complexity and h2 poses another problem (Beaujean, 2005). On these data, Kan’s model must be rejected. And, by the same token, the mutualism model.
5) References.
- Alarcón, M., Plomin, R., Fulker, D. W., Corley, R., & DeFries, J. C. (1998). Multivariate path analysis of specific cognitive abilities data at 12 years of age in the Colorado Adoption Project. Behavior Genetics, 28,255-264.
- Alarcón, M., Plomin, R., Fulker, D. W., Corley, R., & DeFries, J. C. (1999). Molarity not modularity: Multivariate genetic analysis of specific cognitive abilities in parents and their 16- year-old children in the Colorado Adoption Project. Cognitive Development, 14(1), 175-193.
- Beaujean, A. A. (2005). Heritability of cognitive abilities as measured by mental chronometric tasks: A meta-analysis. Intelligence, 33, 187–201.
- Bergeman, C.S., Plomin, R., DeFries, J.C., & Fulker, D.W. (1988). Path analysis of general and specific cognitive abilities in the Colorado Adoption Project: Early childhood. Personality and Individual Differences, 9, 391-395.
- Bishop, E. G., Cherny, S. S., Corley, R., Plomin, R., DeFries, J. C., & Hewitt, J. K. (2003). Development genetic analysis of general cognitive ability from 1 to 12 years in a sample of adoptees, biological siblings, and twins. Intelligence, 31, 31−49.
- Brody, N. (2007). Heritability and the nomological network of g. In M. J. Roberts (Ed.), Integrating the mind: Domain general versus domain specific processes in higher cognition (pp. 427-448). Hove, UK: Psychology Press.
- Cardon, L. R., Fulker, D. W., DeFries, J. C., and Plomin, R. (1992). Multivariate genetic analysis of specific cognitive abilities in the Colorado Adoption Project at age 7. Intelligence 16: 383–400.
- Cardon, L. R., and Fulker, D. W. (1993). Genetics of specific cognitive abilities. In Plomin, R., and McClearn, G. E. (eds.), Nature, Nurture & Psychology, American Psychological Association, Washington, DC, pp. 99-120.
- Casto, S. D., DeFries, J. C., and Fulker, D. W. (1995). Multivariate genetic analysis of Wechsler intelligence scale for children-revised (WISC-R) factors. Behav. Genet. 25: 25-32.
- Davis O. S. P., Haworth C. M. A., Plomin R. (2009b). Learning abilities and disabilities: Generalist genes in early adolescence. Cognitive Neuropsychiatry, 14, 312–331.
- Deary, I. J., Spinath, F. M., & Bates, T. C. (2006). Genetics of intelligence. European Journal of Human Genetics, 14, 690−700.
- Dickens, W. T., & Flynn, J. R. (2001). Heritability estimates versus large environmental effects: The IQ paradox resolved. Psychological Review, 108, 346–369.
- Finkel, D., Pedersen, N. L., McGue, M., and McClearn, G. E. (1995b). Heritability of cognitive abilities in adult twins: Comparison of Minnesota and Swedish data. Behav. Gen. 25:421–431.
- Gignac Gilles E. (2014). Dynamic mutualism versus g factor theory: An empirical test. Intelligence 42: 89-97.
- Hart SA, Petrill SA, Thompson LA, Plomin R (2009). The ABCs of math: a genetic analysis of mathematics and its links with reading ability and general cognitive ability. J Educ Psychol 101: 388–402.
- Hoekstra R.A., Bartels M., Boomsma D.I. (2007) Longitudinal genetic study of verbal and nonverbal IQ from early childhood to young adulthood. Learn Individ Differ 17:97–114.
- Jacobs N, van Gestel S, Derom C, Thiery E, Vernon P, Derom R, Vlietinck R. (2001). Heritability estimates of intelligence in twins: Effect of chorion type. Behav Genet 31:209-217.
- Jensen, A.R., 2006. Clocking the Mind: Mental Chronometry and Individual Differences. Elsevier, Oxford.
- Johnson, R. C., & Nagoshi, C. T. (1990). Resemblances of collateral relatives on cognitive measures as related to g loadings of the measures. Personality and Individual Differences, 11, 871-873.
- Johnson, W., Bouchard, T. J., McGue, M., Segal, N. L., Tellegen, A., Keyes, M., et al. (2007). Genetic and environmental influences on the Verbal-Perceptual-Image Rotation (VPR) model of the structure of mental abilities in the Minnesota study of twins reared apart. Intelligence, 35, 542–562.
- Kan Kees-Jan (2011). The Nature of Nurture: The Role of Gene-Environment Interplay in the Development of Intelligence.
- LaBuda, M. C., DeFries, J. C., & Fulker, D. W. (1987). Genetic and environmental covariance structures among WISC-R subtests: A twin study. Intelligence, 11, 233-244.
- Luciano M, Wright MJ, Geffen GM, Geffen LB, Smith GA, Evans DM, Martin NG (2003). A genetic two-factor model of the covariation among a subset of Multidimensional Aptitude Battery and Wechsler Adult Intelligence Scale–Revised subtests. Intelligence 31:589–605.
- Luciano, M., Wright, M. J., Geffen, G. M., Geffen, L. B., Smith, G. A., and Martin, N. G. (2004). Multivariate genetic analysis of cognitive abilities in an adolescent twin sample. Aust. J. Psychol. 56:79–88.
- Luo, D., Petrill, S. A., and Thompson, L. A. (1994). An exploration of genetic g: Hierarchical factor analysis of cognitive data from the Western Reserve Twin Project. Intelligence 18: 335–347.
- Martin, N. G. & Eaves, L. J. (1977). The genetical analysis of covariance structure. Heredity, 38, 79-95.
- McCall, R. B. (1981). Nature-nurture and the two realms of development: A proposed integration with respect to mental development. Child Development, 1-12.
- McClearn, G. E., Johansson, B., Berg, S., Pedersen, N. L., Ahern, F., Petrill, S. A., et al. (1997). Substantial Genetic Influence on Cognitive Abilities in Twins 80 or More Years Old. Science, 276, 1560–1563.
- Nagoshi, C. T., & Johnson, R. C. (1986). The ubiquity of g. Personality and Individual Differences, 7, 201–207.
- Nichols Paul Leslie (1970). The Effects of Heredity and Environment on Intelligence Test Performance in 4 and 7 Year Old White and Negro Sibling Pairs.
- Panizzon et al. (2014). Genetic and environmental influences on general cognitive ability: Is g a valid latent construct?. Intelligence, 43, 65–76.
- Pedersen, N. L., McClearn, G. E., Plomin, R., & Friberg, L. (1985). Separated fraternal twins: Resemblance for cognitive abilities. Behavior Genetics, 15, 407–419.
- Pedersen, N.L., Plomin, R., Nesselroade, J.R., & McClearn, G.E. (1992). A quantitative genetic analysis of cognitive abilities during the second half of the life span. Psychological Science, 3, 346-353.
- Pedersen, N.L., Plomin, R., & McClearn, G.E. (1994). Is there G beyond g (is there genetic influence on specific cognitive abilities independent of genetic influence on general cognitive ability?). Intelligence, 18, 133-143.
- Petrill, S. A., Luo, D., Thompson, L. A., & Detterman, D. K. (1996). The Independent Prediction of General Intelligence by Elementary Cognitive Tasks: Genetic and Environmental Influences. Behavior Genetics, 26, 135–147.
- Petrill, S. A., Plomin, R., Berg, S., Johansson, B., Pedersen, N. L., Ahern, F., et al. (1998). The Genetic and Environmental Relationship between General and Specific Cognitive Abilities in Twins Age 80 and Older. Psychological Science, 9, 183–189.
- Petrill, S. A., Saudino, K. S., Wilkerson, B., Dale, P. S., & Plomin, R. (2001). Genetic and environmental molarity and modularity of cognitive functioning in two-year-old twins. Intelligence, 29, 31–43.
- Petrill, S.A. (2002) The case for general intelligence: a behavioral genetic perspective. In The General Factor of Intelligence: How General Is It? (Sternberg, R.J. and Grigorenko, E.L., eds), pp. 281–298, Erlbaum.
- Plomin, R., Pedersen, N.L., Lichtenstein, P., & McCleam, G.E. (1994). Variability and stability in cognitive abilities are largely genetic later in life. Behavior Genetics, 24, 207-215.
- Plomin, R., DeFries, J. C., Craig, I. W., & McGuffin, P. (Eds.). (2003). Behavioral genetics in the postgenomic era. Washington, DC: American Psychological Association.
- Plomin, R., DeFries, J. C., Knopik, V. S., & Neiderhiser, J. M. (Eds.). (2013). Behavioral Genetics. Sixth Edition. New York: Worth Publishers.
- Price, T. S., Eley, T. C., Dale, P. S., Stevenson, J., & Plomin, R. (2000). Genetic and environmental covariation between verbal and non-verbal cognitive development in infancy. Child Development, 71, 948–959.
- Rice, T., Fulker, D. W., and DeFries, J. C. (1986). Multivariate Path Analysis of Specific Cognitive Abilities in the Colorado Adoption Project. Behav. Genet. 16:107-125.
- Rice, T., Carey, G., Fulker, D. W., and DeFries, J. C. (1989). Multivariate Path Analysis of Specific Cognitive Abilities in the Colorado Adoption Project: Conditional Path Model of Assortative Mating. Behav. Genet. 19:195-207.
- Rietveld, M. J. H., van Baal, G. C. M., Dolan, C. V., & Boomsma, D. I. (2000). Genetic factor analyses of specific cognitive abilities in 5-year-old Dutch children. Behavior Genetics, 30, 29–40.
- Rijsdijk, F. V., Vernon, P. A., & Boomsma, D. (2002). Application of hierarchical genetic models to Raven and WAIS subtests: A Dutch twin study. Behavior Genetics, 32, 199–210.
- Shikishima, C., Hiraishi, K., Yamagata, M., Sugimoto, Y., Takemura, R., Ozaki, K., et al. (2009). Is g an entity? A Japanese twin study using syllogisms and intelligence tests. Intelligence, 37, 256–267.
- Tambs, K., Sundet, J. M., and Magnus, P. (1986). Genetic and Environmental Contributions to the Covariation Between the Wechsler Adult Intelligence Scale (WAIS) Subtests: A Study of Twins. Behav. Genet. 16:475-491.
- Thompson, L. A., Plomin, R., & DeFries, J. C. (1985). Parent-infant resemblance for general and specific cognitive abilities in the Colorado Adoption Project. Intelligence, 9 (1), 1-13.
- Thompson, L. A., Detterman, D. K., and Plomin, R. (1991). Associations between cognitive abilities and scholastic achievement: Genetic overlap but environmental differences. Psychol. Sci. 2:158–165.
- van der Maas, H. L. J., Dolan, C. V., Grasman, R. P. P. P., Wicherts, J. M., Huizenga, H. M., & Raijmakers, M. E. J. (2006). A dynamical model of general intelligence: The positive manifold of intelligence by mutualism. Psychological Review, 113, 842–861.
- van Leeuwen, M., van den Berg, S.M., Boomsma, D.I. (2008). A twin-family study of general IQ. Learning and Individual Differences 18, 76–88.
- Wainwright, M. A., Wright, M. J., Geffen, G. M., Luciano, M., & Martin, N. G. (2005a). The genetic basis of academic achievement on the Queensland Core Skills Test and its shared genetic variance with IQ. Behavior Genetics, 35, 133–145.
- Wainwright, M. A., Wright, M. J., Luciano, M., Geffen, G. M., & Martin, N. G (2005). Multivariate genetic analysis of academic skills of the Queensland Core Skills Test and IQ highlight the importance of genetic g. Twin Research and Human Genetics, 8, 602–608.
- Walhovd, K. B., & Fjell, A. M. (2007). White matter volume predicts reaction time instability. Neuropsychologia, 45, 2277–2284.
Discover more from Human Varieties
Subscribe to get the latest posts sent to your email.

I find Panizzon et al. 2014 to be very illuminating on the origin of Jensen effects, especially this Fig. 3 from the paper:
Heritability of the latent second-order g is 86%, which is by far the strongest genetic effect across all the latent and observed variables. There are substantial independent genetic effects on three of the four first-order factors and on some of the tests, but all of these specific genetic effects are dwarfed by the genetic g effect. The MCV correlation between subtest g loadings and heritabilities is 0.82.
Subtest heritabilities comprise both the genetic g effect and genetic effects independent of g. If g was the only heritable element in a test battery, then g loadings would be a direct index of heritability. However, in practice there’s always some non-g heritability, which confounds the gxh2 correlation. Sometimes the composition of the battery is such that there’s no Jensen effect for gxh2.
For example, let’s say Panizzon’s test battery consisted only of AFQT Vocab, Digit Span Forward, Digit Span Backward, Letter-Num. Sequencing, D-KEFS #2, and D-KEFS #3. If the factor structure and loadings remained the same as in Fig. 3, the MCV correlation would be -0.26, indicating that heritability is not associated with g. However, even in that case g would be the largest source of genetic variance for all six tests. This means that in individual analyses MCV may produce misleading results, but across many different studies the results should be reliable for the simple reason that g produces large genetic effects across all domains, while non-g sources of genetic effects are “local” and typically small, affecting only some limited domain.
I’m skeptical of chorion effects. In Jacobs et al., the point estimates for MZ correlations for the WISC-R were identical for MC and DC pairs for 2 subtests, higher in MC pairs for 6 subtests, and higher in DC pairs in 4 subtests. The differences were generally tiny. VIQ, PIQ, and full scale IQ correlations were also very similar (differences 0.00-0.03) across chorion types. The chorion differences found by Jacobs et al. look nothing so much as sampling errors.
I have managed to distinct the h2 that belongs to g and the h2 independent of g by looking carefully at the Cardon (1992) study. It triggered a lot of ideas in my mind. Maybe you have noticed already but in your figure 3, speed factor has zero specific genetic loading. You see the same in Cardon (1992) although the same Cardon failed to replicate it in other ages for the CAP data (+ other combined set of data). I hope there is no age effect for the Jensen or anti-Jensen effect on h2 because it renders things very complicated. In any case, the seemingly high relationship between speed and genetic g let me think that we need more studies on chronometric tests.
Another complication (and that’s why the present article took longer before I decide to publish it) is the question of first- and second-order genetic g. Rarely the investigators come to examine the second-order g. Why would inferences of h2 given a first-order genetic g model be acceptable ? After all, at the phenotypic level, a model with first-order g (i.e., no group factors) clearly don’t have the best fit model compared to second-order g with group factors.
For Jacobs (2001) my opinion was obviously not definitive and it is based on only 1 study. Chorion effect is indeed (virtually) null at the test level, but I don’t like the possibility that it may have differential effects on the subtests. It renders MCV even more complicated than it actually is.
Lastly, there is another thing I dislike. In the section “Caveat” you see that I talk about researchers who usually drop c2 parameters if the Chi-Square is not significant. Most of the time, sample size is small, thus non-significant Chi-Square is expected even when c2 is of modest size. You see the same in Panizzon (2014). But, by doing so, when a non-zero c2 is dropped, what do you think happen if variance components must necessarily have a total of 100% ? I let you guess. The dropped c2 is given to h2 which becomes inflated, some subtests more than others if c2 is not equal across all subtests. And c2 is usually never equal across all subtests. So yes, that’s another factor that strongly distorts the g*h2 correlation in a way that is impossible to predict. I disagree with such methods, but unfortunately, the researchers sometimes show you only the reduced (best-fitted) model, and not the full model. Obviously, you’ll not work with the h2 taken from the reduced model. It’s really something dangerous. I remember in one document I have read, where the heritability of Gf was stronger than Gc (or maybe it was the reverse). But in the reduced model (with c2 dropped) there is no difference between Gf and Gc in terms of h2. Hopefully in our meta-analysis, John and I, we have used the full model because we needed the complete ACE components. That’s a chance.
Actually, g is not ‘by far’ the most heritable among the latent variables. It is true that heritability of g is .93^2 hence about .86, but that won’t be significantly higher than that of Verbal Ability, which is (.93*.73)^2+.58^2 hence also about .86, because the heritability of the verbal specific part is also close to that value: (.58^2)/(.58^2+.25^2), hence approximately .84. The heritability of Visual Spatial Reasoning is (.93*.84)^2+.48^2 so about .84 of which the specific part is .48^2/(.48^2+.26^2), hence approximately .77 heritable.The heritability of Working Memory is (.93*.71)^2+.60^2, so about .80. of which the specific part is .60^2/(.60^2+.36^2), so about .74. Ok, speed is clearly the only factor that is not very heritable (about .46, .i.e. (.93*.73)^2), mainly because the heritability of the specific component is 0. If there is a Jensen-effect (I didn’t calculate it), then there is one because of this, that is because Speed has such a low heritability, not because g has such a high heritability. And that speed has such a low heritability is quite strange as it is supposed to ‘underlie’ differences in g in Jensen’s theory (so actually the causal arrow should go from speed to g). If that’s the theory, it cannot explain the high heritability of g.
@ KJK :
“Actually, g is not ‘by far’ the most heritable among the latent variables.”
Given MCV results, positive h2*g-loading suggests such a conclusion. But given multivariate genetic analyses, it’s less obvious. I have said it in the post, I believe, perhaps not clearly enough, however. This being said, my conclusion, which is also similar to Dalliard’s, is that loadings on genetic g is more important than the specific genetic (i.e., the residuals). h2 seems to be confounded with general and specific genetic parameters. And your analyses did not take that into account, that’s why I’m questioning the method employed. Do you disagree with that ? I’m not sure I follow you when you say the zero specific genetics for Speed is due to its lower h2. In Cardon et al. (1992, see table 2) Spatial factor has much lower h2 (0.30) but general and specific genetic loadings are 0.39 and 0.38. For Speed, the numbers are 0.87 and 0.00, and h2 is 0.76. So I don’t understand your argument.
P.S. About your calculation, for Verbal, shouldn’t it be (.93*.78)^2+.58^2=0.86 ?
P.S. 2. (Kan, if you remember, I have said I will write try to submit a paper with my full comment (i.e., critic) to your study, it’s just that I find it hard to collect data on Raven’s correlation with Wechsler’s, that’s why I have decided to search for data on other batteries. I think my paper is already well advanced. You have just to wait a little bit.)
I meant that the genetic effects on g are greater than the independent genetic effects on any other variable. The high heritabilities of the first-order factors reflect the fact that g accounts for most of their variance, both phenotypical (50.4-71%) and genetic (55-100%).
False. If I exclude the Processing Speed tests, the MCV correlation rises to 0.85.
“Given MCV results, positive h2*g-loading suggests such a conclusion” eh no…
If g is real and is the most heritable factor you’ll expect a Jensen effect
does not equal
if you find a Jensen effect you’ll expect g is real and is the most heritable factor
If ghosts are real and scare me I’ll expect my heartbeat to go up
does not equal
if my heartbeat goes up, I’ll expect ghosts are real and have scared me
It’s possible but not neccesarily true
“About your calculation, for Verbal, shouldn’t it be (.93*.78)^2+.58^2=0.86 ”
Yep that’s what I wrote, no?
The picture gives may give the impression that the loading from Ag to g is comparable to the loading from AVerbal to Verbal, but that is not the case. The .58 for ‘A Verbal specific’ is not a standardized loading to the residual but the square root of the genetic part of the residual.. A standardized loading from Averbal to the residual would equal sqrt(.52^2/(.52^2+.25^2)) = .92. That should be the value to be compared with the .93.
You cannot calculate a Jensen effect because the model is not FULLY standardized. It seems the model is only standardized at the level of the latent variables. (The variances in the observed variables do not equal 1)
Or do the variances not add up to because of C contributions are left out? (sorry, I don’t have the original paper)
add up to 1, I mean
As the legend below Fig. 3 says, C components were estimated but are not shown in figure. You don’t have to calculate ACE estimates from the figure as they are reported in Table 1 in the paper.
(edited)
Hi KJK,
We attempted to replicate your r(cultural-load x h^2) results using the 46 batteries here. Refer to the “h^2 g aggregate” sub-page; on the left of the page, you will see the g-loadings and ACE estimates and on the right you will see MH and my assigned cultural loadings, coded roughly based on your guidelines. Our r(cultural-load x h^2) was low (< 0.20) and completely explained by g-load. The results were similar for aggregation (i.e., throwing all subtests together on the assumption that g-loadings are fairly stable across batteries) and meta-analysis.
Any thoughts? Our conclusion was that r(cultural-load x h^2) is driven by r(cultural-load x g) and so consistent with Jensen's model, but less so with yours — as even when controlling for g-load one might expect, by your model, a r (cultural-load x h^2) due to non-g genetic effect. (Maybe not, though.)
We considered emailing you and asking if you wanted to write a follow up, but we weren't sure if the topic still held your interest — so we ended up shelving the idea. But since you commented….
If you are interested, you and your colleagues are welcome to use our data bank. Alternatively, we could do the followup if (a) you went through and checked over our cultural-load coding and (b) explained your model’s predictions in this regards.
I don’t understand what you say here. Because the “If g is real” is very confusing. What do you mean by “real” ? That is, if g is valid as a latent construct ? That is to say, g is not the mere product of external factors, such as mutualistic processes ? Even ignoring this, i don’t follow what you mean here. I mentioned some expected relationship, nothing causal in there.
In any case, what I’m trying to say was that when the more g-loaded subtests appear to be more heritable, it means that when a test becomes more “general” or more “complex” you expect it to be more heritable. All tests measure g to some extent, and some tests measure g much better. I do not imply there is a test that is not g and a test that is g.
Also, I don’t understand your operation again. That should be .58 and not .52, that gives your value of .92. for A-Verbal, which is close to Cardon, it would seem, but I don’t have my answer for the higher genetic loading of Speed on g.
On figure 3, the paths are standardized, as depicted, A1 and E1 are indeed the residuals. If we follow Cardon’s operation, you have =(0.58^2+0.78^2+0.25^2)=1.0073 for Verbal. And (0.73^2+0.00^2+0.68^2)=0.9953 for Speed. Try other factors, it’s the same thing. In other words, Panizzon’s figure 3 is indeed fully standardized, so I have to disagree with your here. Also, your comment about that they have dropped C does not make sense at all. If C is dropped, it is given to A, which becomes inflated. And that’s what they did. The model depicted in figure 3 is their best fitted model, not the ACE “full” model. It’s impossible that the variances don’t add up to 100% just because they have dropped C (or A).
Concerning MCV on Panizzon data, even if you disagree with Dalliard, John Fuerst sent me his result the other day. He used the correlation matrices given in the supplementary data. I look at my XLS file, the g*h2 is 0.690, g*c2 is 0.013, g*e2 is -0.747. By g, I meant PAF1. When I remove the two subtests composing the Speed factor, the respective correlations are 0.667, -0.225, -0.723. So my present conclusion is that both of us are right.
They did not drop the C components. This is what they did:
I don’t see the point in calculating g loadings with PAF from the matrix. The loadings from the hierarchical model in Fig. 3 should be more accurate.
“I don’t see the point in calculating g loadings with PAF from the matrix.”
For the sake of method invariance.
Dalliard :
That’s curious isn’t it. In Shikishima study, figure 3 as well, the variances always add up to 100% but it was stated explicitly that they use AE model. C is dropped. And yet in Panizzon, the variance in latent factors add up to 100% as well even though you don’t see the C. It seems to me that what Panizzon did, and as illustrated in the passage you quote, i.e., “This allowed estimates of the genetic variance and covariance to remain unbiased by common environmental influences”, is that C has been removed at the latent factor level, which is the reason why the variances totalized 100% but according to KJK they don’t add up to 100% for the observed variables (although I did not compute them), perhaps, as they write in their fig.3 the C component has been estimated but simply has not been shown in the picture.
Why they seem to have removed C at the latent factor level is interesting, and suggest that they are fully aware of the problem I have mentioned before. That is, most practioners of model-fitting in genetic studies remove C (or A) when it’s not significant according to chi-square. Take van Soelen study for instance. Look table 5. For youngs, in the ACE, PIQ h2 is 0.46, and c2 was 0.17. In AE, PIQ h2 becomes 0.64. For adolescents, in ACE, c2 was 0.01, thus, as expected, h2 in AE model did not change at all. And yet, absolutely remarkable, they were able to conclude that “Heritability of PIQ was 64% in childhood and increased up to 72% in early adolescence”. With large N, and C being 0.17, I doubt they will have dropped it. That’s clearly different from zero, every way we look at it. This procedure, even though commonly applied, is bad methodology to me. It gives you a distorted conclusion. And just because they always do so does not mean they are right.
That’s the detail that allows me to appreciate the full extent of the quality of Panizzon’s article. It’s not good. No, it is excellent. I would like to see more studies like that.
That said, I take the van Soelen study because it’s relevant to KJK theory of rGE. Say, if rGE is what causing the increasing h2 over ages, I suspect it to have stronger effect on h2 increase for crystallized IQ, i.e., VIQ. But in van Soelen, it’s PIQ, the less cultural, that shows the larger increase in h2. Is it coherent with KJK theory ? Of course, I need to look at more studies before making such conclusion.
with ‘if g is real’, I mean ‘if g is an existing, unitarity, causal variable (like mass) as is according to the graphical model’, hence not just a constructed, multidimensional variable (like general health or athleticism), such that the graphical model would not display the right causal relations.
If you don’t mean g to be a causal variable, then the whole discussion is pointless, because the Jensen effect is expected on the basis of a causal role of g: If g is existing, unitarity, causal variable and if this g is the only source of genetic variance, subtest’s g loadings and heritability coefficients will have a perfect quadratic relationship. The weaker version: If g is existing, unitarity, causal variable and if this g is clearly the largest source of genetic variance, subtest’s g loadings and heritability coefficients will have an imperfect relationship, which – in many cases – can be expected to be positive. (Note that also in a lot of other cases a positive relation between subtest’s g loadings and heritability coefficients can be expected, for example when Verbal ability is the only or main source of genetic variance).
To calculate a Jensen-effect for e^2 makes no sense if e^2 is defined as the residual, which is the case in models such as these.
As I aimed to clarify in my thesis, the MCV is a suboptimal method (this is an understatement).That you still get a Jensen effect in this model (and an even a higher Jensen-effect once you remove speed), is because the first order factors cause it (these are clearly more heritable than the subtests’ residuals; on the latent level there is no Jensen effect. If there is a Jensen effect on the latent level once you put Speed back in, it is because Speed has such a different residual from the other factors, not because g is ‘by far’ the largest source of genetic variance .
To illustrate this I made picture of the role g and specific (non-g) influences in explaining heritability in cognitive factors.
https://dl.dropboxusercontent.com/u/1789435/role%20of%20g%20and%20specific%20factors.jpeg
If g would be the only source of genetic variance (such that the green dots would be in the right corner) you would get a straight line from (0,0) to (1, the heritability of g); the heritability of the cognitive factors would reflect the percentage shared with g (all black dots would faal on the line). If all non-g influences would be as heritable as g, you would expect a horizontal line from (0,heritability of g) (where the green dots would be) to (1, heritability of g). In other words, deviations from the ((0,0) to (1, the heritability of g)) line towards horizontal line reflect the fact that non-g influences contribute to heritabilty of the cognitive factors. Now, if we look at the actual picture, it becomes clear that Speed is the big contributor to a Jensen effect. That the Jensen-effect increases rather than increases on the observed test level shows exactly the flaws of the MCV!
I also redraw part of panizzon model, to present a more fair comparison of the role of specific genes.
https://dl.dropboxusercontent.com/u/1789435/fair%20comparison.jpg
Where did I write .52^2 in stead of .58? I don’t see it.
KJK :
“If you don’t mean g to be a causal variable, then the whole discussion is pointless”
I said that MCV cannot prove g to be a causal entity. And I’m sure you agree with that. You always said that MCV is inefficient in this way. Furthermore, I did not say that g must be more heritable. I thought I was clear enough. MCV suggests that the most g-loaded subtests have more h2 but model-fitting suggests there is no difference in h2 by stratum. It’s even clearer if you look at the Johnson et al. (2007) article on the MISTRA data. Perhaps the difference is because MCV can only analyze the relationship at the subtest level. There is no possibility to weight the models incorporating g and those who don’t incorporate g, such as group factors (correlated or not). On the other hand, complexity in RT measures seem to be related with larger h2. Here again, I don’t know the answer yet. Like I said in my post, we probably need to test the heritable g by using/varying the composition (and nature) of the tests, because it may make a difference.
Concerning your pictures, I may not disagree with you, and I know it’s also what you’ve written in your dissertation. I simply don’t think it’s really a problem that g is not the only heritable component. At the very least, in most cases, a model with g seems to give you the best fit, so that genetic g model is somewhat supported. It’s certainly because there are such high genetic correlations (rG) among the subtest and group factors. When rG is high, what makes people being good at all tests has high genetic component. It’s supportive of Jensen’s theory. Unfortunately, I don’t remember that Jensen had said that if g is not more heritable than non-g components, his theory would be disproved. He said nothing about that. In “The g Factor” (pp 185-188, 194-195) he has cited several studies (MCV and model-fitting) coherent with his view but never explicitly detailed the difference between the two methods and their implications. In MCV, what you test is the differential h2. But in model fitting, you mainly test whether the amount and pattern of rG can allow the presence of higher-order genetic g. Now, suppose that group factors and 2nd higher-order g have same heritabilities, but that the rG among group factors indicate that the genetic effects are not independent, I will interpret this as supportive of jensen’s view. And even more so if the subtests have heritabilities lower than either group or g factor(s).
“Speed has such a different residual from the other factors”
Ok. But why does this explain that Speed has such a high loadings on the (genetic) g and/or no genetic residuals ? You said earlier it’s because Speed has low(er) heritability, that’s not true if you compare Speed with Spatial in Cardon (1992) study. In Panizzon, I can see Speed has the lowest h2, I won’t deny it, but that does not mean there is relationship between the degree of h2 and the amount of genetic residuals.
“To calculate a Jensen-effect for e^2 makes no sense if e^2 is defined as the residual, which is the case in models such as these.”
The point of calculating a Jensen-effect for e^2 was to see if the anti-Jensen Effect on 1-h^2 was on c2, e2, or both.
P.S. the first picture was meant to visualize Jensen’s rationale ‘if g is the main source…’ not to explain the strength of the correlation stength itself, because that depends on many.
Didn’t Panizzon et al fit such a model? https://dl.dropboxusercontent.com/u/1789435/panizzon.png
Surely not.
If you want, ask them to fit your model. I can ask them, but scientists refuse to talk with non-scientists.
In defense of the MCV.
Remember Luo et al. (1994). They found that the phenotypic and genetic g-loadings calculated from phenotypic and genetic intercorrelation matrices produce large correlations but shared and non-shared environment correlation matrices don’t have much correlation with phenotypic g-loadings. When Luo found that, he said it’s coherent with their result from model-fitting.
Wicherts (2004) tested measurement invariance of FE gains notably in Netherlands, but found that a model with higher-order g is tenable (although you need to “free” the parameter of Similarities subtest) which means FE gains in Dutchs can be said to be g-loaded, although the gain is not entirely due to g (because Similarities invariance was not fixed to be the same across cohorts). te Nijenhuis (2012) conducts a meta-analysis of several FE gains in european countries, notably included was the data by Wicherts (2004), and MCV reveals positive FE*g-loadings correlation (for the Wicherts data in Netherlands at least). Again, perfect agreement.
Colom (2002) found, using MCV, that education gain is not g-loaded. Using the same data, Dolan (2006) found the same with MGCFA. A forthcoming article by Abad (2014?), that makes also use of MGCFA, concludes that their result was consistent with the conclusion in Colom (2002). Same thing happens when Dolan (2000) re-analyzed Jensen old data in the test of black-white IQ difference in g.
In most cases, in my memory, when model-fitting and MCV results are compared, they seem to be in agreement. That is worth remembering. Of course, I prefer model-fitting, but I can also appreciate some of the strength of MCV even if I admit its apparent inferiority.
The g factor accounts for perhaps 35% of the variance in Panizzon’s test battery while the non-g variances of the other factors are perhaps 5% each (these are ballpark figures). As the heritability of g is 86%, genetic effects on g explain about 30% of the battery’s total variance, and perhaps 70 percent of the total genetic variance. In contrast, the independent genetic effects on the non-g factors each account for at best a few percent of the total phenotypic variance, and perhaps 20-25 percent of the total genetic variance. I don’t understand how one can infer from these figures that the gxh2 correlation is accidental.
We can all agree that MCV is a suboptimal method, but that doesn’t mean that it cannot tell us anything. Non-g heritability can sometimes influence gxh2 correlations in unexpected ways, but a Jensen effect can be confirmed or disconfirmed in a meta-analysis of many different tests where the non-g genetic effects will play a role consummate with their modest size and scope. Even if some first-order factor was 100 percent heritable and mostly independent of g, it would not matter because its effects would be felt only in some narrow domain rather than across all abilities as with g.
The MCV results regarding g and h2 have been corroborated by multivariate behavioral genetic studies using both twin data and data on unrelated people (multivariate GCTA). Genetic correlations between abilities are consistently high. The advantage of MCV is that it’s very simple and quick to use, and there are copious data to which it can be applied.
Who says I’m saying ‘gxh2 correlation is accidental’?? I’m not (on the contrary; our own research provide ample evidence for it!). I’m just discussing what the relation is supposed to denote. And that is clearly debatable.
Also with reference to your statement “The g factor accounts for perhaps 35% of the variance in Panizzon’s test battery while the non-g variances of the other factors are perhaps 5% each” That’s true, but the following is also true.
“Non-g factors account for perhaps 65% of the variance in Panizzon’s test battery”
And if g is contructivist variable, rather than a real, causal one:
“Non-g infleunces cause 100% of the variance in Panizzon’s test battery”
“I said that MCV cannot prove g to be a causal entity. And I’m sure you agree with that.”
Yep, and that’s not my point
“I did not say that g must be more heritable […] “, no but that is what the MCV intends to provide evidence for, because if g is the more heritable (and if it is the biggest source of variance, and if g is a real [and not a construct, no matter valid or invalid]) it is expected that “the most g-loaded subtests have more h2 “. So, the discussion should be: Ok, we found such a relationship, so what does that tell us? Does it tell us something about our hypothesis that “g is real and is the more heritable, biggest source of variance”? No. But the SEM model and model fit are quite informative: If g is real, it would indeed be among the most heritable sources, and it ii would indeed be the biggest source of variance. But, as we al know, SEM (statistical models) can only discard and never prove. So the strongest what you would have is that ‘the g model is in line with the hypotheses above’. (but it is also inline with reciprocal effects an it is also inline with a sampling model).
“I don’t remember that Jensen had said that if g is not more heritable than non-g components, his theory would be disproved.”
No, but that is also not what I am claiming! I say: ‘ this application of the MCV is intented to be used as providing evidence g is the most, heritable source [which you would expect if g is real and the largest source of variance]’ See Jensen 1998. My problem with the MCV is that it does not provide a statistical test of the underlying hypothesis (which is not ‘gl and h2 correlate’!).
“Now, suppose that group factors and 2nd higher-order g have same heritabilities, but that the rG among group factors indicate that the genetic effects are not independent, I will interpret this as supportive of jensen’s view.” Exactly. And that’s where my comments are always about. Because it is also supportive of a reciprocal effects model and it is also supportive of a sampling model! Therefore, one cannot interpret the fact that ‘factors are genetically not-independent’ as being equal to ‘factors are influenced by generalistic genes’ .
““Speed has such a different residual from the other factors”
Ok. But why does this explain that Speed has such a high loadings on the (genetic) g and/or no genetic residuals ?” Models do not explain things; theories explain (and to test these theories they need to be translated to models) ”
“You said earlier it’s because Speed has low(er) heritability, that’s not true if you compare Speed with Spatial in Cardon (1992) study.” So I was talking about this particular data set. The fact that studies outcomes differ in this is already warning that interpreting statistical factors (including g) as ‘underlying (hence causal) sources’ is dangerous.
“In Panizzon, I can see Speed has the lowest h2, I won’t deny it, but that does not mean there is relationship between the degree of h2 and the amount of genetic residuals.” That’s why the logic behind the MCV is in itself is not invalid. if g is only source of genetic variance (hence genetic residuals are 0), you’ll expect a perfect Jensen-effect; If g is the main source you can expect a correlation between 0 and 1 (but the strength does not tell you much); if g is not heritable you can expect a correlation between -1 and 1 (but the strength does not tell you much). So the support from the literature has come from the fact that the Jensen-effect generalizes across datasets. Nowadays SEM analyses are available, which are for more informative. And with these, the MCV is not necessary anymore. SEM provides the means to test whether the g factor is more heritable and/or the main source.