The strong heritability of IQ is well established for white populations in America, with dozens of studies confirming the basic findings. When it comes to heritability in non-whites, the handful of studies that exist (see Jensen 1998, p. 446ff.; Rowe et al. 1999; Guo & Stearns 2002; cf. John’s recent post) do not allow us to conclude that heritability is lower (or higher) in non-white Americans than it is among white Americans, but there is a sore need for more research.
To diminish this uncertainty, we compared the heritability of several different cognitive abilities in whites, blacks, and Hispanics in the CNLSY sample. The sample, which consists of the children of the mothers who are part of the NLSY79 study, includes the results of various ability tests administered between ages 3 and 13.
Data
The CNLSY is a longitudinal study which surveys the children of the female participants of the NLSY79 study. It has been estimated that about 95 percent of the children of the NLSY79 women are enrolled in the CNLSY. Most of them were born in the 1980s and 1990s.
The CNLSY participants have taken a number of cognitive tests. The tests used are digit span forward (DSB), digit span backward (DSB); the Peabody achievement tests of math (PIAT-M), reading recognition (PIAT-RR), and reading comprehension (PIAT-RC); and the Peabody receptive vocabulary test (PPVT). The tests were administered between 1986 and 2010 when the participants were approximately between 3 and 13 years old.
The analyses that follow present results divided into six age bands: 2-4, 4-6, 6-8, 8-10, 10-12, and 12-14 years. For simplicity, we will refer to these groups as the 3-year-olds, 5-year-olds, 7-year-olds, 9-year-olds, 11-year-olds, and 13-year-olds, respectively. Throughout, our analyses use standard test scores calculated in relation to national standardization samples, with the exception of the digit span tests for which raw scores were used. Within each age band, test scores were residualized for age. Not all tests were administered to all age groups, e.g., the 3-year-olds only did the PPVT. Because of the longitudinal nature of the CNLSY, each child included could contribute multiple test scores to our analysis. However, not all otherwise eligible children were tested in each biennial assessment round. Most analyses in this post use test scores as described above, but for an alternative approach to using the scores, see Analysis III below.
The CNLSY participants differ substantially in age but their test scores were obtained when they were of similar ages. It could be that the Flynn effect would distort the results, giving a score boost to younger children. Indeed, there is a correlation between age and ability in the CNLSY, with those born later tending to score higher. However, in their analyses of the CNLSY, Rodgers & Wänström (2007) and Ang et al. (2010) found that the age effect is mainly explained by the fact that higher-IQ women tend to have children later in life than lower-IQ women. Evidence for the Flynn effect was found only for the PIAT-M test. This indicates that the Flynn effect cannot substantially confound our results.
The CNLSY uses three race/ethnicity categories: black, Hispanic (of any race), and non-black non-Hispanic. This means that the sample that we refer to as ‘whites’ includes all non-black non-Hispanics, i.e., a small number of non-whites, mostly Asians and Native Americans, in addition to the great bulk of whites. Each child’s race was assumed to be the same as that of his or her mother.
Methods
For the behavior genetic analyses, we used the NlsyLinks R package. The package makes it easy to decompose test score variances into additive genetic (A), shared environmental (C), and non-shared environmental (E) components. We used structural equation modeling to fit ACE models to family data.
The A component represents additive genetic influences that make individuals linearly more phenotypically similar the more genetic variants they have in common. The C component represents those environmental influences that make individuals raised together in the same household more similar to each other. The E component, in its turn, records the influence of those unique experiences and random accidents of ontogeny that make individuals less similar to each other. The E component also comprises random measurement error.
The classic twin design based on MZ (identical) and DZ (fraternal) twins reared together is the workhorse of behavior genetics. Unfortunately, the CNLSY was not designed for twin analyses and there are few twin pairs among the participants. However, as the sample includes virtually all the children of thousands of mothers, there are a large number of full sibling and half-sibling pairs in it. In addition, as there are many siblings and other relatives in the NLSY79, many of their CNLSY children are cousins to each other, including first cousins and more distant ones. The NlsyLinks package utilizes the expected coefficients of relationship (CoR) among these pairings (siblings 0.5, half-siblings 0.25, first cousins 0.125, etc.) to estimate the ACE components.
We used two different approaches to estimating the genetic and environmental components. The first is the sibling model which is based only on full and half-sibling pairs. The second is the extended kinship model which includes everything from full siblings to distant cousin pairs. The pairs are non-independent in the sense that each person can be a sibling to one or more persons and a cousin to one or more others.
To give some idea of the data on which the results are based, the following table shows the kinship data for the PIAT-RR test at age 11 in the white sample:

The types of pairs range from third cousins (CoR=0.03125) to MZ twins (CoR=1.0). The 9 pairs with a CoR of 0.375 are “ambiguous siblings” whose true CoR is not known, while those with 0.75 are twins whose zygosity is unknown. Intraclass correlations across different types of pairs are shown in the column named Correlation, and when sample size is sufficient, they generally agree with expectations from the additive genetic model. However, first cousins are more similar than half-siblings, something which is not predicted by any genetic or environmental theory. We found this anomaly in many analyses where cousins were included. I think it may be an artifact stemming from non-independence across cousin pairs.
For this reason, I tend to think that the sibling model is more reliable, although it has its own problems. Namely, as having children by several men is negatively correlated with social class, the half-sibs in our sample are socioeconomically more downscale than that the full sibs. More importantly, half-sibs are much more common in the black sample than in the white and Hispanic samples. The ratio of half- to full sibs in blacks is about 1 to 1, while in whites it is about 1 to 4 and in Hispanic about 1 to 3. This reflects the well-known fragility of monogamy among blacks in particular.
Included in our analyses are only those full and half-sibling pairs who spent at least some of their childhood living in the same household. Cognitive abilities show substantial shared environmental influence in children, which means that ACE components cannot be reliably estimated if the sibling pairs are reared apart. A limitation in our investigation was that we could not ascertain that each pair spent all of their childhood together. Cousins are assumed to not have been brought up together.
Cousin pairs are used in behavior genetic studies from time to time (e.g., Rowe et al. 1999, Hart et al. 2010), but such research seems to rest on a theoretically less robust basis compared to the ubiquitous twin models. Similarly, the theoretical literature on the use of half-sibs in behavior genetic analyses is sparse.
In any case, when we fitted these models to the PIAT-RR data shown in the table above, the maximum likelihood estimates were A=0.72, C=0.08, and E=0.20 for the sibling model, and A=0.61, C=0.14, and E=0.25 for the extended kinship model. As we shall see, differences like this are common between the two models; to some extent this simply reflects sampling variance, but that is unlikely to be the whole story.
The ACE components were estimated separately for the white, black, and Hispanic samples. The objective was to compare the magnitudes of standardized ACE estimates across races. The estimation method relies on the assumption of equal environments for siblings, i.e., full siblings and half-siblings are expected to share trait-relevant environments to the same extent. Another assumption is that no assortative mating took place in the parental generation with respect to cognitive abilities. Violations of the first assumption may inflate heritability estimates, while violations of the second assumption may deflate them.
Technical limitations include our inability to calculate confidence intervals, although this is not a great problem given our large samples. We report ACE estimates for all samples, and do not run tests to investigate whether other models (such as AE models) would fit better.
See Appendices A and B for SPSS and R codes used in carrying out these analyses.
Analysis I: Sibling model
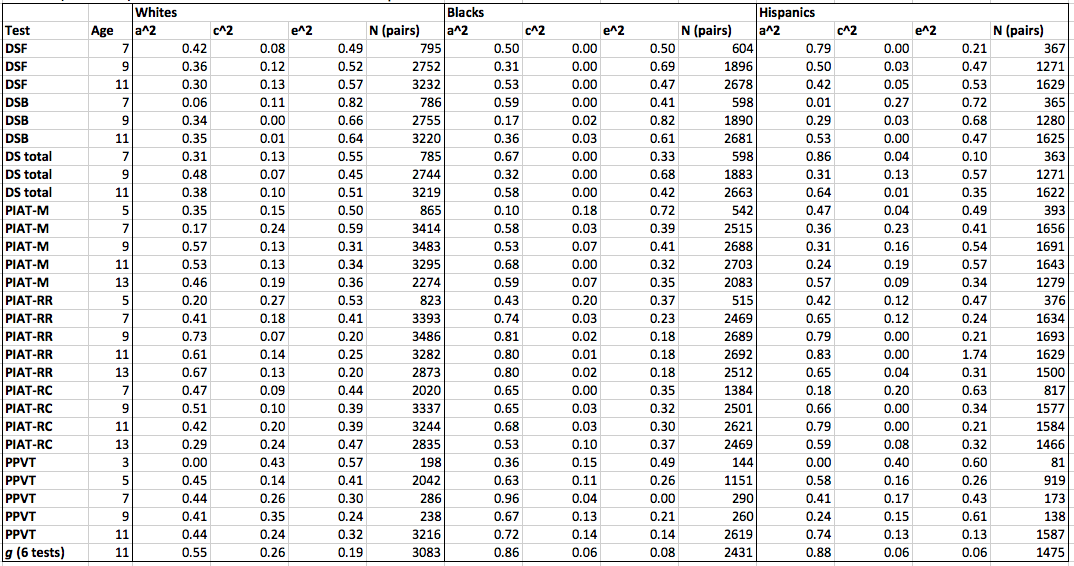
The table below shows the standardized ACE estimates for whites, blacks, and Hispanics by age group and test for the sibling model. a^2 stands for additive heritability, c^2 for shared environment, and e^2 for unshared environment.

Download data: CNLSY-ACE-results-all-rounds.xls
For reasons that are discussed below, the estimates for individual tests appear to be very noisy, and not much attention should therefore be paid to racial differences in ACE components in a particular test. What we are instead interested in are differences in the average ACE variances across all tests and ages. This meta-analytic approach decreases the effects of sampling variance and other artifacts and should give reasonably accurate estimates of population effect sizes.
The next table shows weighted average ACE variances based on all the tests in the previous table, except for the DS total and g tests (which are based on the other tests and excluded as redundant). Sample sizes for each test/age combination correlate at >0.98 between races, giving approximately the same relative weights to the same tests across races. The estimates were calculated as squares of the weighted averages of the square roots of the ACE estimates; in other words, ACE components were first transformed into Pearson’s correlations which were averaged and the results were transformed back into variances. It should be remembered that the samples are not independent, as each individual may contribute many test scores.

These heritability estimates (0.43-0.50) can be regarded as typical for the age range in our sample (3-13 years), but the estimates for the shared environment (0.04-0.08) are somewhat smaller than expected. In these samples and using this method, non-genetic effects are overwhelmingly of the non-shared variety (0.35-0.41). Most relevantly for our purposes, heritability appears to be somewhat greater in whites and Hispanics than blacks, while the influence of the non-shared environment is slightly greater in blacks.
Some racial differences are seen also in the ACE estimates for g scores, reported in the first table, which were derived from scores on digit span forward and backward, PIAT-M, PIAT-RR, PIAT-RC, and PPVT tests taken at age 11. Genetic variances are 0.61 for whites, 0.55 for blacks, and 0.60 for Hispanics. The fact that the g scores are based on multiple tests should make the results reasonably reliable.
Analysis II: Extended kinship model
Results from the extended kinship model are shown below. a^2 stands for additive heritability, c^2 for shared environment, and e^2 for unshared environment.
Download data: CNLSY-ACE-results-all-rounds.xls
The average ACE variances from this extended kinship analysis look like this:

Unlike in the sib analysis, the Hispanic and especially the black heritability estimates are higher than the white ones. The difference is particularly conspicuous for g scores at age 11.
Analysis III: Averaged-across-rounds scores
There are several different approaches to obtaining ACE estimates from the large and heterogeneous collection of test scores available in the CNLSY data. Above, we estimated the ACE components for each test and age group separately, and averaged the obtained variance components. Alternatively, one may average the test scores across all tests, ages, and test rounds, and use the average scores in ACE analyses. Because each participant typically completed a number of different tests at different ages, these average scores reflect, to some extent, the longitudinal stability of mental ability.
So, we averaged each participants’ standard scores across all testing rounds (1986-2010) for each test (digit span total, PIAT-M, PIAT-RR, PIAT-RC, and PPVT). Additionally, we computed g scores for each individual based on those across-the-years average standard scores. Below, the results of applying the sibling ACE model to these test scores are shown:

And here are the ACE estimates for the same data using the extended kinship model:

Download data: ACE-estimates-for-average-scores.xls
Similarly to Analyses I and II, the extended kinship model suggests that heritability is greater in blacks and, to some extent, Hispanics than whites, while the sibling model suggests that heritability is lower in blacks.
Discussion
The pattern of different heritabilities and environmentalities across various tests discovered in our investigation does not necessarily indicate that the determinants of different abilities are substantially variable. There are several weaknesses in the data and methods used that tend to render all individual parameter estimates very noisy. These weaknesses include:
2) Systematic sampling errors. Some tests were administered selectively. For example, the PIAT-RC test was given only if the subject got a sufficiently high score on the PIAT-RR.
3) Poor psychometric properties. Some test score distributions were substantially non-normal, and the interval property of the scales used may have been more compromised than is usual with cognitive tests. Reliabilities differed between tests. See Winship (2003) for a discussion of the psychometric shortcomings of the tests used in the CNLSY.
4) Non-representative samples. Our analyses were based on all sibling and cousin pairs in the CNLSY. Because the original NLSY79 included oversamples of, for example, poor individuals, the CNLSY children cannot be regarded as representative of the US population.
5) Uncertainty associated with the behavior genetic models used. The sibling and the extended kinship models produce somewhat different parameter estimates.
One might think that little can be salvaged from these results due to these problems, but we would argue that the meta-analytic averaging of parameter estimates (or test scores, as in Analysis III) greatly enhances the signal in the data and cancels out error. It does not seem that the results are greatly biased with respect to race/ethnicity, at least as far as problems 1-4 go. Estimates for individual tests may be biased by the aforementioned flaws, but as we have dozens of different sets of ACE estimates for each group, there is reason to believe that the overall results are broadly reliable.
Unfortunately, it seems clear that either the sibling model or the extended kinship model (or both) is biased with respect to race. Depending on which estimates you choose, heritability is either similar or lower or higher in whites compared to non-whites; the differences are too large and systematic to be put down to sampling errors. It is very difficult to say which method is the more reliable one, or how much bias there is. I suspect that the problem is non-independence across pairs (i.e., each individual can be a member of several kinship pairs), combined with the fact that the frequency of different kinship types differs between races.
We set out to find out if race or ethnicity moderates the extent of IQ heritability in America, but unhappily the present investigation cannot shed much light on that question. The most we can say is that cognitive abilities appear to be very substantially heritable regardless of race in the CNLSY.
If I had to choose the one of the several sets of ACE estimates that appears to be the least problematic, I would point to Analysis I. It suggested that the heritability of IQ may be somewhat lower in blacks as compared to whites and Hispanics in this child sample. This is not implausible given the generally more disadvantaged environmental circumstances of blacks (none of the Hispanics in the CNLSY are first-generation immigrants). On the other hand, the difference is not large (6 or 7 percentage points), and genetics appears to be the largest component of variance in blacks, too.
References
Ang, S., Rodgers, J. L. & Wänström, L. (2010). The Flynn Effect within Subgroups in the U.S.: Gender, Race, Income, Education, and Urbanization Differences in the NLSY-Children Data. Intelligence, 38, 367–384.
Hart, S. A., Petrill, S. A., & Dush, C. M. K. (2010). Genetic influences on language, reading, and mathematics skills in a national sample: An analysis using the National Longitudinal Survey of Youth. Language, speech, and hearing services in schools, 41, 118-128.
Jensen, A. R. (1998). The g factor: The science of mental ability. Westport, CT: Praeger.
Rodgers, J. L. & Wänström, L. (2007). Identification of a Flynn Effect in the NLSY: Moving from the center to the boundaries. Intelligence, 35, 187–196.
Rowe, D. C., Jacobson, K. C., & Van den Oord, E. J. (1999). Genetic and environmental influences on vocabulary IQ: Parental education level as moderator. Child development, 70, 1151-1162.
Winship, S. (2003). Early Warning: The Persistence of Cognitive Inequalities at the Start of Schooling.
Appendix A: SPSS syntax
This file contains the SPSS syntax for recoding CNLSY test scores according to age at test. It also creates test scores residualized for age within age bands, and computes age-11 g scores. These scores were used in Analyses I and II.
SPSS syntax for creating the kinds of average test scores used in Analysis III is available here. It also creates g scores.
Appendix B: R code and miscellanea
The R code for obtaining ACE estimates from CNLSY sibling data is given below. The CNLSY data are in the file named whites.csv. You can replace DSF_AGE_7 with other test variable names.
rm(list=ls(all=TRUE))
require(NlsyLinks)
dsLinking <- subset (Links79Pair, RelationshipPath=="Gen2Siblings")
filePathOutcomes <-'/Users/user/Desktop/whites.csv'
dsOutcomes <- ReadCsvNlsy79Gen2(filePathOutcomes)
dsSingle <- CreatePairLinksSingleEntered (outcomeDataset=dsOutcomes, linksPairDataset=dsLinking, outcomeNames= c('DSF_AGE_7'))
oName_1 <-"DSF_AGE_7_1" #Stands for Outcome1
oName_2 <-"DSF_AGE_7_2" #Stands for Outcome2
dsGroupSummary <-RGroupSummary(dsSingle, oName_1, oName_2)
dsGroupSummary
dsClean <-CleanSemAceDataset(dsDirty=dsSingle, dsGroupSummary, oName_1, oName_2)
ace <-AceLavaanGroup(dsClean)
ace
The R code for obtaining ACE estimates from CNLSY extended kinship (=siblings and cousins) data is given below. The CNLSY data are in the file named whites.csv. You can replace DSF_AGE_7 with other test variable names.
rm(list=ls(all=TRUE))
library(NlsyLinks)
filePathOutcomes <-'/Users/user/Desktop/whites.csv'
dsOutcomes <- ReadCsvNlsy79Gen2(filePathOutcomes)
dsOutcomesSubset <- dsOutcomes
dsLinks <- Links79PairExpanded
dsSingle <- CreatePairLinksSingleEntered (outcomeDataset=dsOutcomesSubset, linksPairDataset=dsLinks, outcomeNames= c('DSF_AGE_7'))
oName_1 <-"DSF_AGE_7_1" #Stands for Outcome1
oName_2 <-"DSF_AGE_7_2" #Stands for Outcome2
dsGroupSummary <-RGroupSummary(dsSingle, oName_1, oName_2)
dsGroupSummary
dsClean <-CleanSemAceDataset(dsDirty=dsSingle, dsGroupSummary, oName_1, oName_2)
ace <-AceLavaanGroup(dsClean)
ace
For what it’s worth, here’s yet another set of ACE estimates from the CNLSY. The approach used is rather similar to Analysis III in the main text, but we regard Analysis III as more reliable.

Amazingly brilliant!
I will circulate this around as well as likely add it to my HBD Fundamentals page.
Thanks. The results here are somewhat equivocal because different ACE models don’t give invariant results. We have been working on a meta-analysis of race and IQ heritability, which hopefully will be published at some future date.